AI in het onderwijs, waarom zijn ethische richtlijnen nodig?
Het wordt meer en meer duidelijk dat artificiële intelligentie of AI een meerwaarde kan zijn in ons onderwijs. AI heeft het potentieel om leerervaringen van leerlingen persoonlijker te maken, beoordelingen te automatiseren, automatisch feedback te geven en sneller leerproblemen te identificeren. Om alle mogelijkheden die je hebt goed te gebruiken, is het belangrijk dat je weet wat AI is, hoe de technologie werkt en wat de voordelen voor het onderwijs zijn. Maar ook dat je de risico’s en ethische aandachtspunten kent. In dit artikel leggen we dat allemaal uit.
Wat is artificiële intelligentie?

Artificiële intelligentie ontwikkelt zich zo snel, dat de technologie moeilijk te definiëren is. De Raad van Europa combineert daarom 2 definities.
“AI is een verzameling van wetenschappen, theorieën en technieken die het cognitieve vermogen van een mens wil reproduceren door een machine. Nieuwe ontwikkelingen zijn er bijvoorbeeld op gericht om AI moeilijke taken te laten uitvoeren die vroeger door de mens werden gedaan.”
“AI verwijst naar op machines gebaseerde systemen die
op basis van doelstellingen die de mens definieert beslissingen kunnen nemen en voorspellingen en aanbevelingen kunnen doen die een invloed hebben op reële of virtuele omgevingen. AI-systemen communiceren met ons en beïnvloeden onze omgeving direct of indirect. Vaak lijken ze zelfstandig te werken en kunnen ze hun gedrag aanpassen door te leren over de context.”
Van algoritme tot resultaat
In mensentaal: AI bestaat uit een reeks instructies, een algoritme. De computer volgt dat algoritme om een taak uit te voeren en tot een resultaat te komen. Zo’n algoritme kun je vergelijken met een recept waarin je stappen volgt om tot een resultaat – het gerecht – te komen. Het algoritme van AI is soms zo complex dat het een neuraal netwerk wordt genoemd omdat het op de denkpatronen in onze hersenen lijkt. Daarmee bedoelen we: AI kan gegevens detecteren en interpreteren en op basis daarvan zelfstandig handelen.
Waar vind je artificiële intelligentie?
Op heel veel plaatsen, vaak zonder dat je het weet.
Je smartphone zit vol AI. AI voorspelt de woorden die je typt, herkent scènes, mensen en voorwerpen in je foto’s en vermindert je batterijgebruik door te analyseren hoe je je smartphone gebruikt. Soms zit AI ook in dingen waar je het niet meteen verwacht. Een gekke filter zetten op een selfie? Ook artificiële intelligentie.
Ook muziekstreamingdiensten zitten vol AI. Ze stellen muziek voor op basis van je luistergeschiedenis, analyseren het ritme, het tempo en de genres van liedjes om ze automatisch in lijsten te bundelen en scannen muziek op spam en/of illegale inhoud.
Misschien zit er ook in je elektrische tandenborstel wel AI. Analyseert hij je manier van poetsen en geeft hij je feedback om dat beter te doen? Juist: AI.
Ook (zelfrijdende) auto’s gebruiken AI om verkeersborden en andere weggebruikers te scannen of om te voorspellen wat andere weggebruikers zullen doen.
Hoe werkt artificiële intelligentie?
Het algoritme, het recept van AI, wordt gevoed met gegevens. Dat kan je leeftijd zijn, hoe vaak je in een stad of winkel komt, welke tv-programma’s je kijkt, welke zoektermen je in een zoekmachine ingeeft …
Maar ook teksten, foto’s, geluidsfragmenten en programmeercode. Al die gegevens samen noemen we een dataset. Hoe groter de dataset, hoe beter het algoritme. Een AI-programma is dus maar zo sterk als de dataset die erachter zit.
Zelflerende machines
Een AI-programma gebruikt verschillende manieren van machine learning om tot resultaten te komen. Via machine learning kunnen computerprogramma’s zonder tussenkomst van de mens zelf leren en beslissingen nemen. Zo is er software die zichzelf leerde schaken door duizenden partijen schaak te spelen en te analyseren. Die schaaksoftware is niet te verslaan door de mens.
Er zijn verschillende vormen van machine learning:
- Stap 1
Supervised learning
Bij supervised learning of gecontroleerd leren wordt het AI-programma getraind met gegevens die door de mens gelabeld zijn. Zo kun je de computer bijvoorbeeld duizenden foto’s van huizen en auto’s geven. Bij elke foto staat of het een huis of een auto is. Het programma analyseert al die foto’s en herkent of het bij nieuwe foto’s om een auto of een huis gaat. Wie al die gegevens labelt? Jij en ik!
Wanneer je ergens inlogt, moet je soms een captcha-controle invullen om te bewijzen dat je geen robot bent. Dan ben je eigenlijk een AI-programma aan het trainen. Door de juiste afbeeldingen aan te klikken, label je ze en versterk je de dataset.
- Stap 2
Unsupervised learning
Unsupervised learning of ongecontroleerd leren wordt gebruikt als het stappenplan of algoritme nog niet duidelijk is, maar je wel veel gegevens hebt om aan het programma te geven. Je rekent erop dat het programma zelf patronen, relaties en verbanden vindt. Het programma doet dat door te clusteren: gegevens groeperen op basis van gelijke kenmerken.
Een mooi voorbeeld is een klantenkaart. Het AI-programma detecteert patronen in je aankoopgedrag en interpreteert die gegevens: koop je altijd vis op vrijdag of veel speelgoed in de periode voor sinterklaas? Op basis van die interpretaties en groeperingen krijg je doelgerichte advertenties.
- Stap 3
Reinforcement learning
Bij reinforcement learning of leren uit versterking geef je het algoritme een beloning als het resultaat goed is en een straf als het fout is. Het programma wil zo veel mogelijk beloond worden door zo vaak mogelijk het juiste resultaat te geven. Reinforcement learning vind je in zelfrijdende auto’s. Die moeten rekening houden met snelheidslimieten en verkeersborden, rijstroken respecteren, ongelukken vermijden …
Als je het algoritme in een testomgeving allerlei situaties doet ervaren en die als goed of slecht labelt, leert het algoritme hoe de auto moet reageren.
- Stap 4
Deep learning
Deep learning of diepgaand leren is gebaseerd op de neurale netwerken van ons brein. Het AI-programma gebruikt verschillende lagen om te leren en te beslissen. Hoe meer lagen, hoe ingewikkelder de opdracht die het kan oplossen. Het nadeel: meer lagen betekent ook dat je het algoritme moeilijker kunt trainen en dat de trainingscomputer veel rekenkracht nodig heeft. Zelfs zo veel rekenkracht dat deep learning nog niet lang een succes is.
Enorm complex
Elke laag bestaat uit informatie die het algoritme uit de gegevens haalt. De keerzijde van de medaille: deep learning is zo complex dat er een zwarte doos ontstaat. Hoe meer lagen, hoe minder transparant voor de mens. Je weet niet meer wat het AI-programma doet tussen de gegevens die je het geeft en het resultaat.
Alle lagen analyseren
Kennisnet maakt deep learning duidelijk met dit voorbeeld.
1 laag analyseert de vorm van de vogel, een andere de kleur, nog eentje de achtergrond, enzovoort. Geef je het algoritme een foto van een andere vogel? Dan gebruikt het al die verschillende lagen om de foto te analyseren en in te schatten om welke soort vogel het gaat. Deep learning werkt ook in de andere richting: afbeeldingengeneratoren gebruiken weleens zo’n meerlagig algoritme.
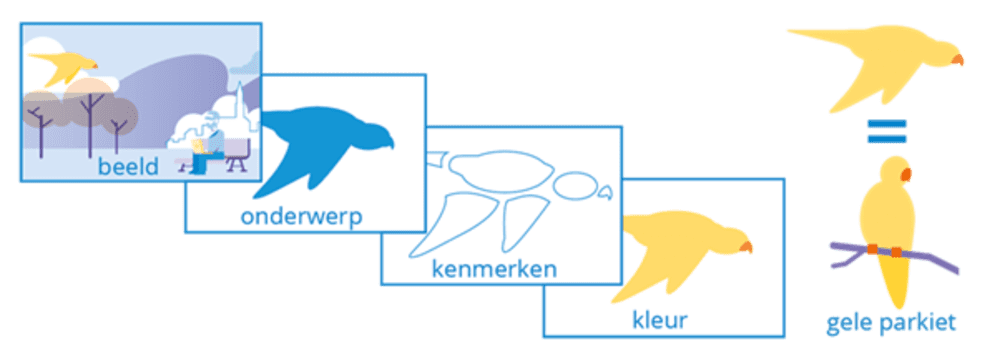
Wat is de relatie tussen AI en gegevens?

We gebruiken AI-programma’s meer en meer, ook in het onderwijs. Zoekmachines, slimme assistenten, chatbots, vertalingssoftware, navigatieapps, online videospelletjes, … Ook verschillende andere toepassingen die we elke dag gebruiken, draaien op AI. Die AI-programma’s gebruiken op hun beurt gegevens die ze op verschillende manieren en in verschillende vormen – bijvoorbeeld als beeld, geluid of tekst – krijgen.
Zonder data geen artificiële intelligentie.
AI-programma’s genereren zélf nieuwe gegevens
AI maakt zelf nieuwe gegevens aan en gebruikt die vaak om zich sterker te maken. Die nieuwe gegevens kunnen de resultaten van het programma zijn, maar ook de zoektermen die de gebruiker ingeeft. Ook in het onderwijs kunnen heel veel verschillende gegevens de dataset vormen. Een AI-programma kan die gegevens per leerling verzamelen:
- Hoeveel keer klikt een leerling per oefening?
- Hoelang doet een leerling over een oefening?
- Hoe vaak oefent een leerling?
- Welke tik- en spellingfouten maakt de leerling het meest?
- Met welke klasgenoten heeft de leerling het meeste contact?
- Waar logt de leerling het vaakst in: op school of thuis?
- Welk type toestel en browser gebruikt de leerling?
Dat zijn maar enkele voorbeelden van gegevens die een online leerplatform kan verzamelen. De mogelijkheden bij andere toepassingen zijn vaak nog groter.
Waarom heeft het onderwijs ethische richtlijnen nodig?
AI heeft alles in zich om een meerwaarde te zijn in onze scholen. De technologie kan een positieve invloed hebben op de leerpraktijk en je als leraar en schooldirectie ondersteunen en ontzorgen. Een AI-programma kan bijvoorbeeld helpen om:
- leerbehoeften sneller in kaart te brengen
- gepersonaliseerde leerervaringen aan te bieden
- als school beslissingen te nemen, bijvoorbeeld over een vervolgopleiding na het 6de leerjaar
- administratieve taken te automatiseren en te versnellen.
Zet je AI-programma’s op een goede manier in? Dan kun je als school ook je (leer)middelen efficiënter inzetten.
Gevolgen en risico’s
Maar omdat AI-programma’s zichzelf blijven ontwikkelen en verbeteren, groeit ook hun dataset aan. Daardoor neemt het datagebruik langzaam toe. Het is dus belangrijk om dat datagebruik en de mogelijke gevolgen en risico’s die dat voor ons heeft, goed te begrijpen. Het moet voor de gebruiker duidelijk zijn welke gegevens het AI-programma verzamelt.
Zeker wanneer het gegevens van kinderen en jongeren verzamelt zoals in het onderwijs. Als onderwijsprofessional moet je dus de basis kennen van AI en weten hoe de programma’s gegevens gebruiken. Alleen zo kun je kritisch en ethisch met de technologie aan de slag.
Hoe beheren AI-programma’s hun gegevens?
De grote hoeveelheid gegevens die AI-programma’s nodig hebben om goed te werken, roepen samen met hun automatiserende karakter vragen op over gegevensbescherming. AI-programma’s die niet goed ontworpen zijn of onzorgvuldig worden gebruikt, kunnen schadelijke gevolgen hebben.
Als onderwijsprofessional moet je weten en je afvragen of de AI-programma’s die je gebruikt wel betrouwbaar, rechtvaardig en veilig zijn en of ook de gegevens veilig worden beheerd. Het moet ook duidelijk zijn hoe ze de privacy van de leerlingen beschermen.
5 bedenkingen
AI is niet perfect. We moeten stilstaan bij de mogelijke nadelige gevolgen van AI in het onderwijs. Enkele kritische bedenkingen:
- Stap 1
De resultaten van AI zijn gebaseerd op gegevens. In een dataset kunnen onbewust vooroordelen sluipen die de resultaten beïnvloeden. Soms zorgen historische gegevens voor een vertekend beeld omdat de situatie vroeger anders was dan nu.
Voorbeeld: resultaten van een AI-programma dat afbeeldingen maakt, bevatten soms stereotypen op basis van huidskleur, geslacht of leeftijd. Zo krijg je voor ‘professor’ vaak een oudere, blanke man als resultaat. Alleen maar omdat heel lang bijna alleen maar mannen en amper vrouwen professor waren.
- Stap 2
AI is heel indrukwekkend en is heel vaak juist. Maar niet altijd. Soms zegt het algoritme hoeveel procent het zeker is van het resultaat. AI-programma’s kunnen de bal dus misslaan. Ze kunnen een koolmees foutief labelen als een pimpelmees. Dat kan geen kwaad. Maar wat als het AI-programma van een auto een verkeerssituatie verkeerd inschat met een ongeluk als gevolg?
Er bestaan al verschillende leerprogramma’s die AI gebruiken om leerlingen te helpen in hun leerproces. Omdat AI niet perfect is, kunnen ze foute adaptieve inhoud krijgen. Ook de conclusies die zo’n leerprogramma aan leraren geeft zijn vaak juist, maar niet altijd. Als onderwijsprofessional moet je daar rekening mee houden wanneer je in het dashboard van zo’n leerprogramma werkt.
- Stap 3
Vertrouwen we te veel op AI? Dan beginnen we minder kritisch en probleemoplossend te denken. Het grote gevaar daarvan: we laten AI onze problemen oplossen, waardoor we er afhankelijk van worden.
Voorbeeld: sommige leerlingen gebruiken altijd online hulpmiddelen zoals vertaalprogramma’s, chatbots of spellingscorrectie wanneer ze voor school werken. Zo worden ze er afhankelijk van en weten ze niet meer wat te doen als ze geen toegang tot AI hebben.
- Stap 4
Soms kan het moeilijk zijn om te bepalen wie verantwoordelijk is als er iets fout loopt.
Voorbeeld: leerlingen gebruiken AI-software die hen adaptieve leerpaden aanreikt. Achteraf blijkt dat het programma gegevens fout interpreteerde. Gevolg: ze verloren kostbare leertijd en liepen een achterstand op. Wie is verantwoordelijk?
- Stap 5
AI gebruikt gegevens die het moet verzamelen. In het onderwijs betekent dat: grote hoeveelheden leerlingengegevens analyseren en verwerken.
Voorbeeld: als school beslis je om een innovatief leerplatform te gebruiken. De resultaten zijn verbluffend en de leerprestaties van je leerlingen gaan snel vooruit. Achteraf blijkt: in de gebruiksvoorwaarden staat dat de verzamelde gegevens aan andere partijen kunnen doorverkocht worden.
Ethische richtlijnen EU

Daarom stelde de EU ’ethische richtsnoeren voor het gebruik van artificiële intelligentie en data bij onderwijzen en leren voor onderwijsactoren’(PDF bestand opent in nieuw venster) op. Zo krijg je inzicht in alle mogelijkheden die je met AI-programma’s en datagebruik hebt en word je je bewust van de mogelijke risico’s. Zo kun je positief, kritisch en ethisch met AI-programma’s werken en hun potentieel ten volle benutten.
Kunnen we je helpen?
Foutje gezien? Een link die niet werkt? Laat het ons weten!
Krijg je graag ergens meer informatie over? We bekijken je vraag en zien wat we kunnen doen.
Schrijf je in op onze nieuwsbrief
Blijf je graag op de hoogte van de laatste nieuwtjes? Schrijf je dan nu in voor onze maandelijkse nieuwsbrief.
Tools

