Waarom dit handboek?
Gedaan met laden. U bevindt zich op: 4. Hoe begin ik als (lokale) overheid aan open data? Handboek 'Open Data voor lokale besturen'
4. Hoe begin ik als (lokale) overheid aan open data?
In dit hoofdstuk worden een aantal stappen en vragen behandeld die je in overweging dient te nemen wanneer je als (lokale) overheid open data wil beschikbaar maken.
Eerst en vooral is het belangrijk om inzicht te verwerven in de maturiteit van jouw lokaal bestuur met betrekking open data en jezelf bewust te worden van de meerwaarde van open data. Bijgevolg ligt hoofdstuk 4.1 de quick scan voor open data van het Smart Flanders toe en verduidelijkt waar dit handboek verschillende meerwaarde van open data in detail bespreekt.
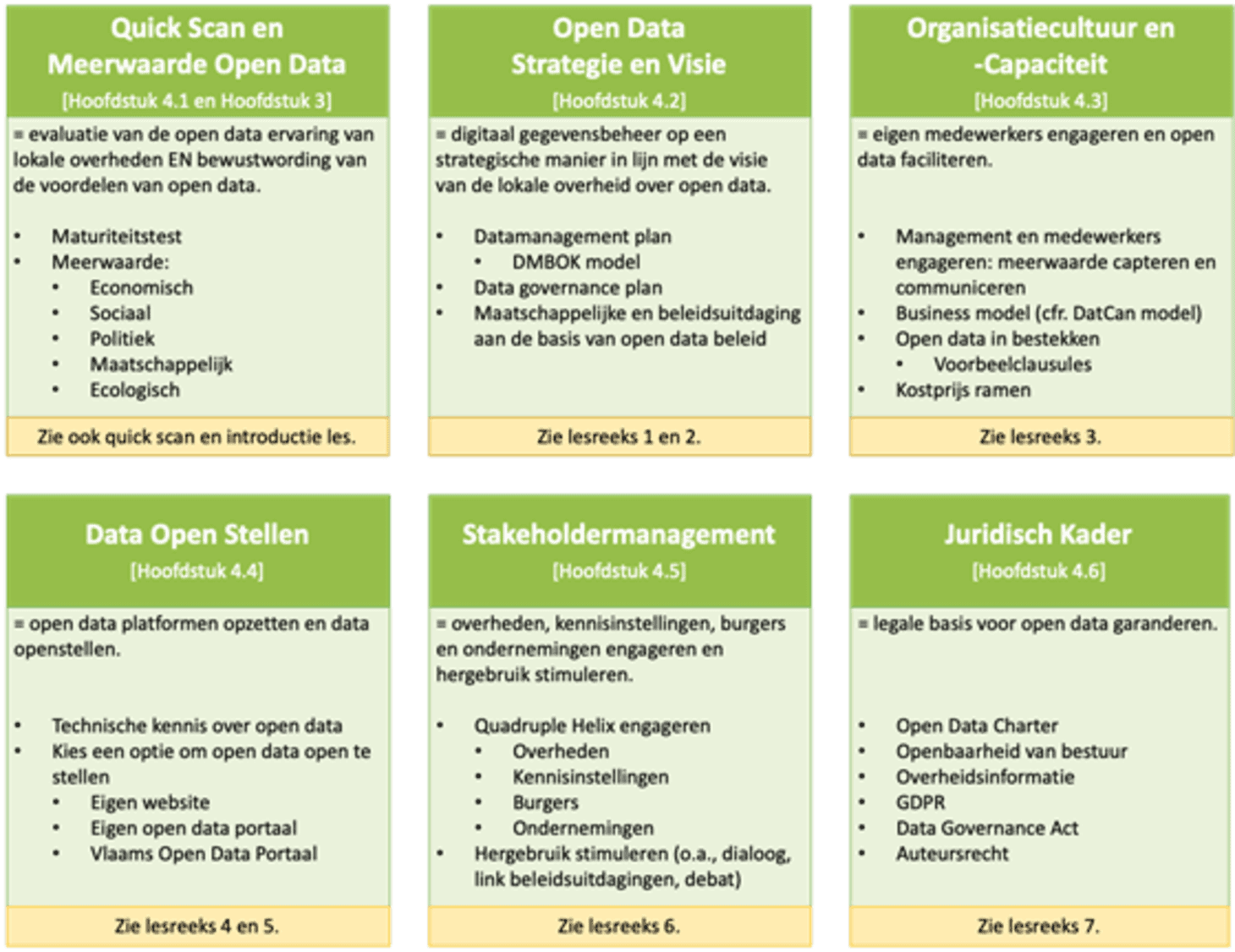
Met een goede kennis van de open data maturiteit en meerwaarde, kan je zelf aan de slag gaan met open data of een bestaand open data beleid verder gaan optimaliseren. Gezien er veel elementen zijn om rekening met te houden in een overheidscontext, heeft dit handboek alles samengevat voor jou in vijf categorieën: (1) open data strategie en visie, (2) organisatiecultuur en -capaciteit, (3) data open stellen, (4) stakeholdermanagement, en (5) juridisch kader. Deze vijf categorieën worden in hoofdstuk 4.2 tot en met 4.6 gedetailleerd toegelicht. Enkele additionele tips worden telkens samengevat in een overzichtelijke tabel aan het einde van elke hoofdstuk.
Vervolgens vat hoofdstuk 4.7 de belangrijkste aanbevelingen nog eens samen en geeft dit ook weer in een overzichtelijk stappenplan.
Aanvullend heeft Smart Flanders ook een online leeromgeving ontwikkeld om (lokale) overheden zelf aan de slag te laten gaan met de materie uit dit hoofdstuk op een interactieve manier: online leeromgeving.
De afbeelding onder vat heel dit hoofdstuk 4 samen en geeft een overzicht van de elementen die belangrijk zijn voor lokale overheden om open data beschikbaar te maken (zie groene kaders). Vervolgens wordt elk deel telkens gelinkt aan de lesreeks(en) van de online leeromgeving (zie gele kaders).
4.1.2 Open data meerwaarde
Naast het niveau van maturiteit van de lokale overheid, dien je ook bewust te zijn van de meerwaarde die open data kan creëren voor alle diverse stakeholders van het open data beleid van de lokale overheid. Om een overzicht te verwerven van deze veelvuldigheid aan voordelen verwijzen we naar hoofdstuk 3 alsook hoofdstuk 4.5.1. In deze onderdelen van het handboek bespreken we in detail de diversiteit aan voordelen van open data (cfr. economische, sociale, politieke, maatschappelijke, ecologische voordelen) voor een waaier van stakeholders (cfr. overheden, kennisinstellingen, ondernemingen en burgers).
4.2 Datastrategie en visie

Het is duidelijk dat data een belangrijke rol opneemt in elke organisatie, inclusief lokale overheden. Dat was altijd al het geval, maar de digitale transformatie dwingt ons om extra aandacht te hebben voor digitaal gegevensbeheer. In dit kader zijn ‘datamanagement’ en ‘data governance’ uitermate relevant. Onderstaande paragrafen geven een algemeen overzicht van de meest voorkomende raamwerken om met gegevensbeheer in het kader van open data te starten.
4.2.1 Datamanagement
Gegevensbeheer of “datamanagement” in de literatuur heeft als doelstelling om “waarde” uit data te extraheren. Om deze waarde (zie hoofdstuk 3) uit data te kunnen extraheren moet deze data typisch aan een aantal eigenschappen (zie afbeelding):
Voorbeeld: DATAMANAGEMENT IN VLAANDEREN
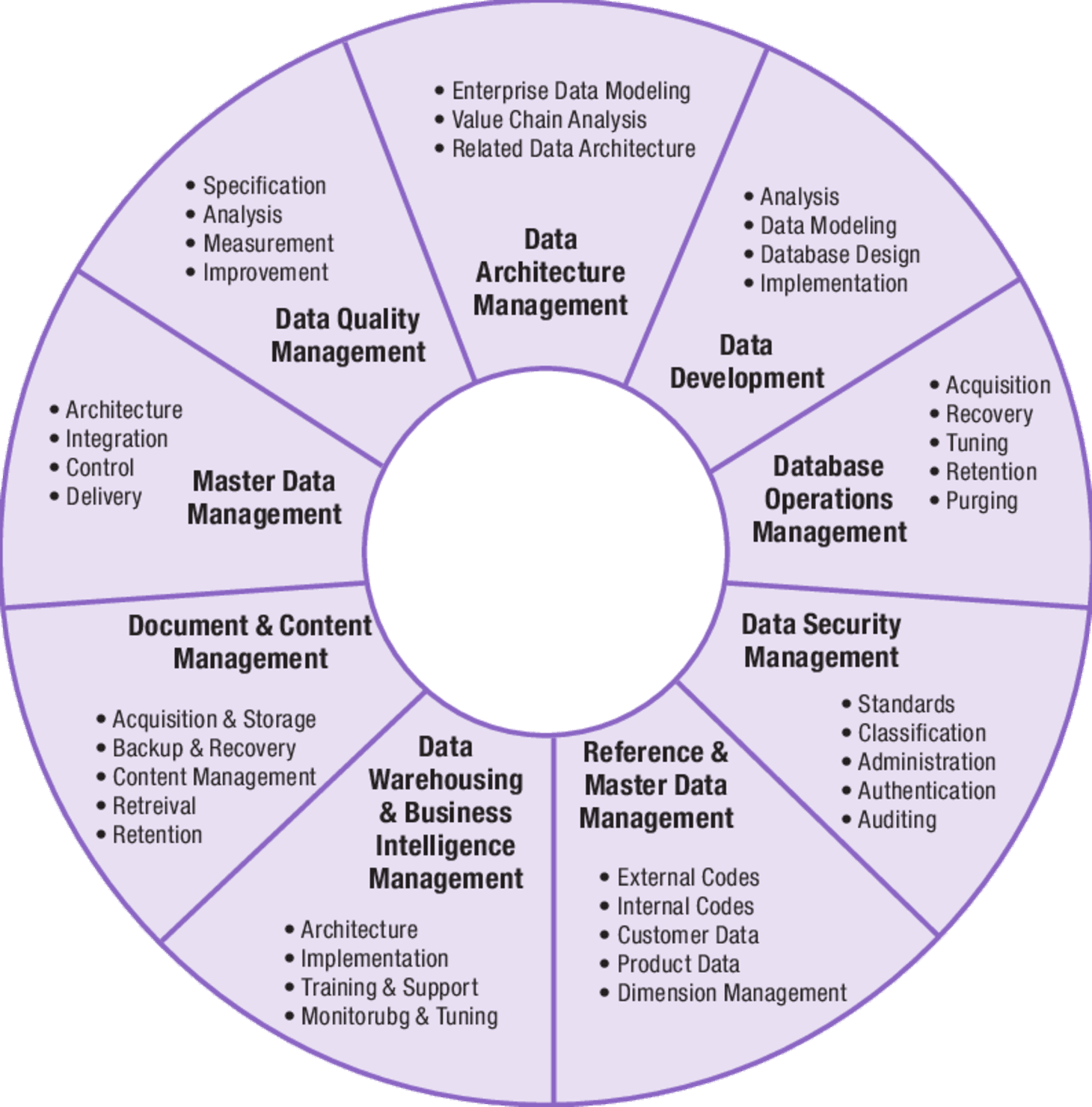
De meest courante geciteerde bron voor deze discipline is de “DMBOK” (“Data Management Book of Knowledge”). Hierin wordt datamanagement beschreven als het geheel van deze activiteiten (zie afbeelding):
Stappenplan: aan de slag met Data Management
- Stap 1
Korte en langetermijn doelen in kaart brengen (cf. beleidsdoelen en organisatiedoelen)
Eerst en vooral moeten de doelen van het data governance plan worden geïdentificeerd en afgetoetst met het management. Hiervoor is het aangewezen om de algemene beleids- en organistatiedoelen te bekijken en ook om te identificeren hoe datamanagement hieraan kan bijdragen. Bijvoorbeeld, indien de organisatie in besparingsmodus is, zal het data governance plan de nadruk leggen op een rationalisatie van het datalandschap, bijvoorbeeld door verschillende databanken te integreren.
- Stap 2
Informatielandschap in kaart brengen (bv. bestaande data, datanoden, mogelijke technologieën)
Om het informatielandschap in kaart te brengen kan men best een rondgang organiseren doorheen de verschillende departementen en diensten. Indien voorhanden kan er ook uitgegaan worden van een proceskaart. Indien niet, kan een eenvoudig gesprek met de medewerkers snel inzichten brengen. Het is niet de bedoeling om hier in veel detail te treden, maar gewoon om een helikopter-overzicht te krijgen van welke soort gegevens er doorheen de organisatie verwerkt worden, hoe dit gebeurt, en welke vragen er leven.
- Stap 3
Levenscyclus van informatie
Bij het in het kaart brengen van het informatielandschap sta je best ook stil bij hoe de gebruikte gegevens evolueren over de tijd. Een voorbeeld: een adres is voor vele lokale besturen een belangrijk datapunt. Een adres is echter geen statisch gegeven, denk bijvoorbeeld aan een nieuwbouwhuis. Een adres wordt aangevraagd, gecreëerd, gevalideerd, mogelijks aangepast en uiteindelijk soms afgeschaft.
- Stap 4
Databronnen inventariseren
Vervolgens gaan we voor de belangrijkste soorten informatie de gebruikte databronnen identificeren. Dit kunnen er een of meerdere zijn. Zij kunnen in eigen beheer zijn of in het beheer van een leverancier, partner of andere overheid. Opnieuw in het geval van een adres, zal dit veelal in beheer zijn van de Vlaamse overheid, met name in het CRAB. Het is echter niet ondenkbaar dat er intern kopieën worden bijgehouden, dat er parallelle adreslijsten bestaan, en dat die vaak niet 1 op 1 gelinkt zijn aan het CRAB.
- Stap 5
Pijnpunten identificeren
Als volgende stap worden de pijnpunten geïdentificeerd. Ook dit zal blijken uit de rondgang doorheen de departementen en diensten. Veel voorkomende problemen zijn ontbrekende data, slechte datakwaliteit of extra werk door ontdubbelde databronnen.
- Stap 6
Kerndatasets identificeren
Kerndatasets zijn datasets die cruciaal zijn voor de werking van de organisatie. In het geval van een lokale overheid kunnen dat er heel wat zijn. Om hier wat structuur in aan te brengen kan men bijvoorbeeld refereren naar het beleidsplan of de BBC, en uitgaan van het prioritair beleid. Ook worden kerndatasets vaak gekenmerkt door het feit dat ze in veel verschillende processen worden gebruikt, doorheen verschillende diensten en departementen.
- Stap 7
Beleid, processen en documentatie inventariseren
Voor elk van de kerndatasets brengen we vervolgens in kaart voor welk beleid zij relevant zijn, welke processen er gebruik van maken, en welke documentatie er al dan niet voorhanden is. Is er bijvoorbeeld een entity-relationship model voorhanden voor de belangrijkste databanken?
- Stap 1
Data stewards identificeren
Het is belangrijk om in kaart te brengen wie er binnen de organisatie het meest betrokken is bij datagebruik. Dit zal ook duidelijk worden bij de rondgang doorheen de departementen/diensten. Deze personen zijn ideaal gepositioneerd om een rol op te nemen als data steward. Indien er bijvoorbeeld per dienst een ICT-coördinator is kan het goed zijn dat zij goede kandidaten zijn, maar mogelijks zijn er anderen beter gepositioneerd.
- Stap 2
Gegevensbeheercomité samenstellen
Al deze datastewards samen vormen het gegevensbeheercomité. We brengen mensen uit verschillende delen van de organisatie samen voor twee belangrijke redenen. Allereerst zodat zij ook inzien dat bepaalde beslissingen inzake gegevensbeheer impact hebben op anderen. Ten tweede omdat het op die manier makkelijker wordt om ook het belang van andere databronnen in te zien. Mogelijks kunnen er aan dit gegevensbeheercomité ook leden van het hoger management worden toegevoegd, dit kan zorgen voor een betere buy-in.
- Stap 3
Eerste databron identificeren om te optimaliseren
Bij het in kaart brengen van het informatielandschap zal al snel duidelijk worden dat bepaalde databronnen kunnen worden geoptimaliseerd. Bijvoorbeeld, omdat hergebruik moeilijk is, omdat de kwaliteit te laag is, of omdat er grote kosten worden gegenereerd door deze te laten beheren door een externe leverancier. Het is niet mogelijk om alles ineens aan te pakken. Daarom laten we het gegevensbeheercomité beslissen welke de eerste databron is die moet worden geoptimaliseerd. Dit zorgt ineens ook voor gedragenheid binnen de organisatie.
- Stap 4
Benodigde middelen inschatten
Wanneer de eerste te optimaliseren databron is geïdentificeerd, schatten we in welke middelen nodig zullen zijn om dit te doen. Dit kan sterk variëren afhankelijk van de aanpak. Zo kan er een nieuwe aanbesteding nodig zijn, of kan er via een aantal eenvoudige procesoptimalisaties al een verbetering worden gerealiseerd. Wanneer de juiste aanpak is gedefinieerd wordt er navenant budget gevraagd aan het management, met de duidelijke boodschap dat dit slechts een eerste stap is.
- Stap 5
Nulmeting uitvoeren
Om goed te kunnen rapporteren is het belangrijk dat er ook een nulmeting wordt uitgevoerd. Dit is geen eenvoudige zaak. We proberen in te schatten hoeveel kosten er gepaard gaan met het verwerken van die eerste databron. Dit kan een combinatie zijn van VTE kosten en licenties die worden betaald aan leveranciers. Het kan ook zijn dat (een deel van) de data periodiek moet worden aangekocht. Al deze kosten samen vormen de nulmeting.
- Stap 6
Eerste verandering doorvoeren
Wanneer het budget is goedgekeurd kan de eerste verandering worden uitgevoerd. Het is daarbij belangrijk om steeds het gegevensbeheercomité op de hoogte te houden en het project goed te managen. Deze verandering kan eenvoudigweg een procesverandering zijn, maar kan ook een ICT-project inhouden.
- Stap 7
Winst inschatten
De verschillende kostenposten die werden geïdentificeerd moeten na de verandering opnieuw worden ingeschat. Dit zal (hopelijk) leiden tot een winst, zij het in ICT kosten, zij het in personeelsinzet. Vervolgens zetten we dit af tegen de kost om de verandering door te voeren. Het is belangrijk om deze winst in te schatten over de tijd. De kost van een ICT-investering wordt daarbij typisch afgeschreven over 5 jaar, maar het kan zijn dat uw organisatie een andere periode hanteert.
- Stap 8
Terugkoppelen naar het management / sponsors
We communiceren de doorgevoerde verandering vervolgens aan het management, zowel inhoudelijk als financieel. Vervolgens vragen we het mandaat om verder te gaan met het uitwerken van een data governance plan.
- Stap 1
Data governance plan opmaken (roadmap definiëren) en valideren
Wanneer er mandaat wordt verkregen voor het verder uitwerken van een data governance plan, gaan we aan de slag. In nauwe samenwerking met het gegevensbeheercomité werken we een roadmap uit die aangeeft hoe en wanneer we verschillende databronnen optimaliseren. Het is daarbij belangrijk om rekening te houden met de ICT-roadmap, indien die bestaat, maar zeker ook om onderlinge afhankelijkheden in kaart te brengen. Het gegevensbeheercomité moet deze roadmap goedkeuren.
- Stap 2
Middelen verzekeren
We vragen het management om de roadmap te valideren en de nodige middelen te verzekeren.
- Stap 3
Iteratief veranderingen doorvoeren
Voor elke stap in de roadmap hanteren we hetzelfde proces zoals beschreven voor de eerste dataset.
- Stap 4
Voortdurend meten en terugkoppelen
Om een blijvende gedragenheid te voorzien voor het data management programma blijven we bij elke verandering nul- en eindmetingen doorvoeren en koppelen we steeds terug naar het gegevensbeheercomité en het hoger management.
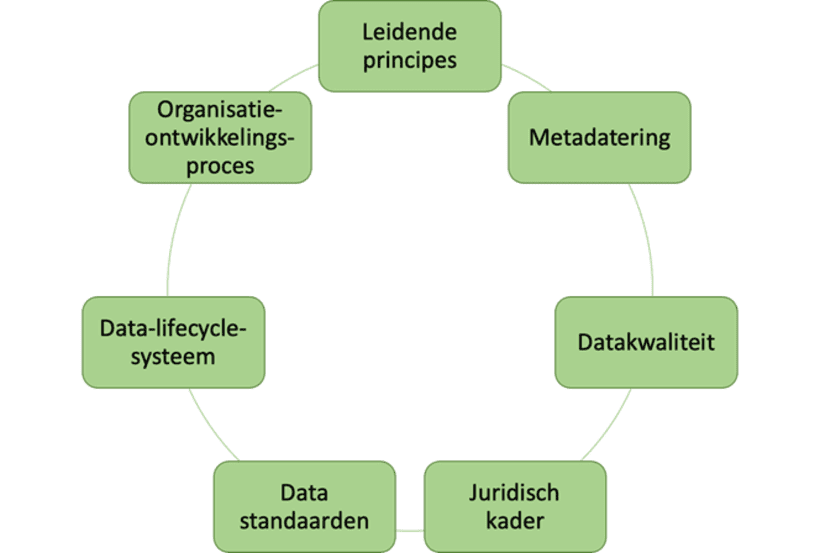
4.2.2 Data governance
Besturen die data willen ontsluiten als open data, botsen vaak op enkele vraagstukken: welke data moeten we ontsluiten, waar bevinden die data zich in onze organisatie, of hebben we die data überhaupt, wie zal onze data gebruiken, en hoe ontsluiten we deze data? Deze en andere vragen roepen om een structuur en een beleidskader: een vorm van data governance. Hieronder geven we een aantal aspecten mee die deel uitmaken van een goede data governance. Merk op dat dit ook centraal staat in bovenstaande afbeelding rond datamanagement en data governance. Dit betekent dat data governance raakt aan alle andere activiteiten die met datamanagement te maken hebben, maar het maakt er dus wel een integraal deel van uit. Om een goed datamanagement plan op te stellen, is het belangrijk om met een paar belangrijke elementen rekening te houden (zie afbeelding). Volgende paragrafen gaan dieper in op deze elementen van een goed data governance beleid.
Bij de ontwikkeling van een data governance-structuur leg je in de eerste plaats leidende principes vast die sturend zijn voor de omgang met open data. Focuspunten hierbij zijn de toegang tot de data verzekeren, een databeleid opzetten en uitdragen, standaarden gebruiken die ervoor zorgen dat softwaresystemen met elkaar kunnen communiceren én een wederzijds begrip hebben van de betekenis van de data.
Je moet dus aandacht besteden aan het feit dat data beschikbaar zijn en dat ze teruggevonden kunnen worden, zowel door andere overheden als door potentiële (her)gebruikers. Data zijn ook niet altijd inzichtelijk zonder context: een tabellenreeks, ellenlange opsommingen van tijdsfragmenten of loutere cijfers spreken vaak niet voor zich. Metadatering is hierbij cruciaal (zie hoofdstuk 2.1.4). Deze contextinformatie is noodzakelijk om de data te kunnen interpreteren en te linken. Hieronder beschrijven we de metadata die gecapteerd wordt voor Geopunt. In hoofdstuk 2.1.4 werken we ook het voorbeeld uit van de specifieke website van Digitaal Vlaanderen voor metadata om het eenvoudig terugvinden van open data te stimuleren.
Voorbeeld: METADATA GEOPUNT
Binnen data governance kijken we ook naar het aspect datakwaliteit. Daarbij gaat het ten eerste over de volledigheid van databestanden. Bepaalde gegevens kunnen verloren gaan of niet gecapteerd worden bij de dataverzameling. Dit moet natuurlijk vermeden worden, maar desgevallend wordt dit meegegeven als metadata bij het bestand. Ten tweede denkt men bij datakwaliteit aan het formaat waarin de data ontsloten worden. Bij een goede data governance stel je gegevens zo veel mogelijk open in machine-leesbare formaten. Ten derde wordt ook de klemtoon gelegd op hoe het databestand gestructureerd wordt. Het gebruik van ‘open standaarden’ wordt daarbij nagestreefd, maar idealiter geef je in de metadata ook het gehele datamodel mee dat gehanteerd wordt. Op die manier kunnen (her)gebruikers snel inschatten op welke manieren ze de gegevens al dan niet in andere toepassingen kunnen binnenbrengen.
Een ander belangrijk element van goed databeleid is de afstemming met juridische kaders die het (her)gebruik van de data vastleggen door middel van licenties, en die bescherming bieden bij veiligheids- en privacy-issues. Hierbij geldt in eerste instantie een voorzichtigheidsbeginsel, waarbij je persoonsgegevens niet openlijk publiceert, maar waarbij je ook nagaat of geanonimiseerde gegevens na publicatie niet opnieuw geïdentificeerd kunnen worden. Het gebruik van licenties laat toe om het (her)gebruik te bepalen, maar ook – door de keuze van bronvermelding te verplichten – dat de waarachtigheid van de gegevens gevalideerd kan worden. Wanneer je als organisatie een consistent datagedrag nastreeft, ontstaat zowel intern als extern meer zekerheid over wat er met de data gedaan kan worden en voor welk doeleinde. De keuze van licenties bepaalt ook in welke mate derden zelf de open data kunnen beheren. In dit kader, wordt in hoofdstuk 2.3 het Open Data Charter besproken en gaat hoofdstuk 4.6 dieper in op het juridische kader van starten met open data als (lokale) overheid.
Eén van de belangrijkste juridische vraagstukken is, zoals hierboven aangegeven, het publiceren van open data zonder een inbreuk te maken tegen de GDPR. Echter, maar al te vaak wordt deze verordening aangegrepen als reden om data niet te publiceren. Desalniettemin blijft een lokale overheid gebonden aan de Open Data Act. We moeten met andere woorden een afweging maken tussen deze twee juridische kaders. Veel gegevens die door lokale overheden worden verwerkt hebben inderdaad te maken met personen, maar dat betekent niet dat we in globo moeten afstappen van het publiceren van deze gegevens als open data. Integendeel, persoonsgebonden gegevens kunnen een enorme meerwaarde betekenen voor middenveldorganisaties en eender wie die belang heeft bij het inschatten van bijvoorbeeld socio-economische indicatoren binnen een stad, gemeente, wijk, of buurt. Om dit toch mogelijk te maken introduceren we anonimisatie.
Anonimisatie behelst het herstructureren van een dataset zodanig dat individuen niet langer identificeerbaar zijn. Om dit te kunnen doen moet men vaak beroep doen op statistici of “data scientists”. Het is tevens het expertisedomein van de DPO. Anonimisatie is geen eenvoudige materie, maar het anonimiseren en het vervolgens publiceren van overheidsgegevens kan vaak een grote meerwaarde creëren, al is het maar om inschattingen te kunnen maken over de leefwereld van de bewoners van de stad of gemeente. Als we, telkens wanneer er persoonsgegevens voorkomen in een dataset, afzien van de publicatie ervan als open data, eindigen we met enkel levenloze en vaak oninteressante gegevens.
Er is heel wat literatuur voorhanden inzake anonimisatie. Er zijn veel technieken om dit te doen op het niveau van een specifieke dataset maar we moeten erkennen dat in deze gedigitaliseerde wereld, het steeds mogelijk blijft om verschillende datasets (zoals die van sociale media) te combineren om een individu toch te kunnen isoleren. Het publiceren van datasets die geanonimiseerde persoonsgevens bevatten blijft met andere woorden een zeer moeilijke en vaak ethische overweging. Een oude, maar toch relevante opinie over deze kwestie werd gegeven door de “Article 29 Working Party(opent in nieuw venster)” van de Europese Commissie. De meest voor de hand liggende technieken om data te anonimiseren zijn:
- Pseudonimisatie
- Met deze techniek zorgen we ervoor dat persoonsgegevens, zoals een naam of adres, veranderd worden naar niet-gerelateerde datapunten. Dit kunnen verzonnen alternatieven zijn. Belangrijk om op te merken is dat we bij deze techniek niets veranderen aan de structuur van de dataset. Individuele datapunten (records) blijven individuele datapunten, zij het met andere inhoud.
- Aggregatie
- De veiligste manier om te anonimiseren is door datapunten te aggregeren in cohorten. In plaats van individuele records te publiceren, publiceren we gegevens die geaggregeerd zijn over een geografisch gebied, over leeftijdscategorieën, of over andere categorieën toepasbaar op de inhoud van de dataset.
- Obfuscatie
- Deze techniek wordt vaak toegepast bij het publiceren van broncode van software. Toegepast op data betekent dit dat de onderlinge relaties tussen datapunten behouden blijven maar dat het onmogelijk wordt om individuele eigenschappen te lezen. Om dit te doen zal men bijvoorbeeld een versleutelingsalgoritme toepassen zodat namen, adressen, enzovoort niet meer kunnen achterhaald worden, maar dat het nog steeds mogelijk blijft om relaties te leggen tussen verschillende records.
Wanneer je grote hoeveelheden data gaat uitwisselen, is het belangrijk om goede afspraken te maken tussen de uitwisselende organisaties. Via vastgelegde of veel voorkomende datastandaarden kan je gegevens makkelijker integreren en kunnen machines hiermee aan de slag zonder dat je de gegevens nog manueel moet overhevelen of integreren. Een datastandaard is een afspraak over de structurering van gegevens, zowel in databases, spreadsheets, of gegevens die je op een website publiceert. Een datastandaard wordt ook door verschillende partijen gezamenlijk onderschreven als de norm. Via datastandaarden wordt interoperabiliteit of samenwerking tussen systemen nagestreefd, zodat men in principe onafhankelijk is van systemen van ICT-leveranciers. Meer informatie of datastandaarden kan je raadplegen in lesreeks 4 “Werken met data” van de online leeromgeving. Vermits deze standaarden ook cruciaal zijn om verschillende data(sets) te linken wordt dit concept ook verder behandeld in hoofdstuk 6.3.
Datastandaard in Vlaanderen: DCAT-AP
Ook belangrijk is een data-lifecycle-systeem. Dit geldt zowel voor data voor intern gebruik als voor open gepubliceerde data. Met een data-lifecycle-systeem beschrijf je een procedure hoe je als organisatie de data archiveert, hoe je intern zult omgaan met nieuwe versies van databestanden, en hoe je dit aan de buitenwereld communiceert. Ook hier is metadateren van groot belang.
Tot slot is het menselijke aspect een belangrijke voorwaarde. De focus op data vraagt veelal een organisatieontwikkelingsproces dat zowel in de geesten als in het gedrag van de medewerkers een aanzienlijke verandering vraagt. Het besef van de mogelijkheden van zorgvuldige en correcte gegevens laat toe om aan betere beleidsontwikkeling te doen. Hiertoe moet er binnen de organisatiecultuur een datafocus komen. Dit kan bijvoorbeeld door intern datawerkgroepen op te zetten.
Data-stewards in je organisatie
Bij de oprichting van een datawerkgroep of datakring zijn twee belangrijke elementen van tel. De betrokkenheid van de communicatiedienst kan een meerwaarde hebben, omdat die vaak het websitebeheer in handen heeft, en vaak ook de laatste schakel is in de publicatie van ‘content’ (en dus ook data) op de website. Tegelijkertijd betrek je ook de softwareleveranciers mee in de dialoog, omdat besturen deze diensten vaak aankopen. Zij bepalen via hun producten hoe en wat er met de data gebeurt. We onderstrepen graag hoe belangrijk het is dat de overheidsorganisatie zelf het stuur vastneemt in deze dialoog. Door leveranciers te betrekken in topics die datakringen behandelen, krijgen softwareleveranciers ook een beter inzicht in wat van hen verwacht kan worden.
Een onderwerp dat niet op de agenda van deze werkgroepen mag ontbreken, is dataflows. Hierbij streef je het ‘only-once’-principe na, waarbij je gegevens eenmalig creëert en dan laat doorstromen naar andere diensten en softwarepakketten. Deze dataflows in kaart brengen vraagt een inspanning, maar maakt de (samen)werking efficiënter. Daarenboven ontstaat er inzicht voor de organisatie: welke data hebben we? Waar zitten die verspreid? Wie maakt gebruik van deze data? En hoe ‘bewegen’ deze gegevens doorheen onze interne processen tussen diensten?
Dit laatste brengt ons bij het aspect van de rol van technologie in de organisatie. Technologie an sich is veelal niet het uitgangspunt, maar het is wel de technologie die zo goed als alle businessprocessen faciliteert. De meeste lokale besturen kopen technologie aan bij leveranciers in een kant-en-klaar product. Het kan voorkomen dat er vooraf niet nagedacht werd over welke data verzameld zouden worden of hoe die data doorstromen binnen de verschillende applicaties van de organisatie. Ook de mogelijkheid om de verzamelde data als open data te publiceren wordt vaak over het hoofd gezien. Om aan dit interoperabiliteitsprobleem (i.e. problemen in verband met samenwerking tussen verschillende datasets) tegemoet te komen, verwijzen we naar de principes van het Open Data Charter in hoofdstuk 2.3. Verder zal hoofdstuk 4.4 ook dieper ingaan op de nodige technische aspecten om te starten met open data.
4.2.3 Welke data? De beleidsuitdagingen definiëren
Data openstellen beschouwt men vandaag nog vaak als iets technisch. Je hebt er een informaticus voor nodig, een goed draaiende ICT-infrastructuur en een performante website of zelfs een open data portaal. Hoewel deze elementen in verschillende mate belangrijk zijn ter ondersteuning, is de eerste vraag waarom je data zou openstellen. Toen het concept ‘open data’ aan populariteit won, werden data vaak enkel geopend ‘om te openen’. Hoewel dit zeker niet zonder verdienste was en vaak interessante inzichten opleverde over hoe de overheid (al dan niet) met open data kon omgaan, bleef de impact van dergelijke initiatieven vaak beperkt.
Vandaag is de aanpak geëvolueerd en vertrek je vanuit het waarom en de potentiële meerwaarde van open data in functie van beleidsuitdagingen. Denk bijvoorbeeld aan de mobiliteitsproblematiek: wanneer er voldoende (real-time) open data beschikbaar zijn over de situatie op de weg, de dienstregeling en actuele toestand bij het openbaar vervoer, de beschikbaarheid van deelfietsen en informatie over de weersomstandigheden, wordt het mogelijk om (route)plannerapplicaties te bouwen die met al deze elementen rekening houden. Wanneer je als bestuur open data gericht kunt inzetten om (een deel van) een maatschappelijke uitdaging aan te pakken, is er meteen een meerwaarde voor alle betrokken partijen: voor de organisatie die de data ter beschikking stelt, voor de (her)gebruikers die er nieuwe toepassingen mee maken, én voor de gebruikers van die toepassingen.
In plaats van te starten met de data die ‘het meest op orde staan’ of het makkelijkst te ontsluiten zijn, start je best vanuit de inhoudelijke vraag en identificeer je een maatschappelijke uitdaging. Deze uitdaging wordt vormgegeven met de nodige diensten binnen de overheidsorganisatie. Pas in tweede orde ga je na welke datasets ontsloten moeten worden om deze uitdaging (ten dele) aan te pakken en welke organisaties deze data eventueel kunnen beheren.
Deze aanpak vraagt echter een doorgedreven betrokkenheid van de overheidsorganisatie en is zeker geen gemakkelijke oefening. Je moet een keuze durven maken voor een bepaald thema en vervolgens een beleidskwestie expliciet en in detail benoemen. De keuze voor een kwestie kan immers gestuurd worden door de politiek, de administratie, belangen van derde partijen of andere, eerder contextuele factoren.
Identificeer de beleidsuitdaging
4.2.4 Algemene tips voor een goede open data strategie en visie
Hieronder geven we nog enkele algemene tips mee die belangrijk zijn voor het operationaliseren van een goede open data strategie en visie.
Open data strategie en visie – Algemene tips
Lokale Besluiten als Gelinkte Open Data (LBLOD)
Stimuleren en innoveren van de (lokale) economie
Vaak vragen besturen zich terecht af of het implementeren van een open data programma wel de moeite loont. Veelal wordt de meerkost en het minimaal gebruik van de open data in kwestie als tegenargument aangehaald. Het is immers niet altijd duidelijk welke baten een open data programma genereert. Indien men zich echter beperkt tot het louter wettelijk verplichte is het veelal zo dat men de kosten wel ervaart maar de baten niet realiseert.
Een belangrijk deel van die baten situeert zich bij het stimuleren van economische actoren en van innovatie. Het is onwaarschijnlijk dat die baten zich op korte termijn manifesteren, of dat zij rechtstreeks terugvloeien naar het lokale niveau. Zoals we in hoofdstuk 3 hebben gezien en in hoofdstuk 4.5 verder uitdiepen zullen we zien dat het absoluut wel mogelijk om hier een aantal voorbeelden van te zien.
Er werden reeds meerdere studies uitgevoerd om deze meerwaarde te kwantificeren. Een vaak geciteerde bron is de analyse van McKinsey(opent in nieuw venster) van 2013. Het onderzoek van McKinsey wijst namelijk uit dat het openbaar beschikbaar maken van (publieke en private) data wereldwijd drie miljoen dollar aan economische waarde creëren op slecht zeven sectoren (namelijk: onderwijs, transport, consumentengoederen, elektriciteit, olie en gas, gezondheidszorg, en consumentenfinanciering).
Het is niet zonder reden dat de Europese Commissie beslist heeft om een strategie(opent in nieuw venster) te definiëren rond het gebruik van (open) data. Men schat in dat de data-economie in Europa momenteel 2,6% van het algemene Europese BNP bepaalt, maar dat slechts 8% van de Europese economische actoren er werkelijk in slaagt om data te valoriseren. Het potentieel is dus enorm.
Om dit potentieel te ontsluiten is essentieel om deze innovatieve mogelijkheden van open data te begrijpen en te ontsluiten naar medewerkers om zo een open data cultuur binnen de organisatie te creëren. Hierbij kunnen lokale overheden verwijzen naar rapporten zoals dit van McKinsey. Daarnaast kunnen ook data(visualisaties) van Provincie in Cijfers(opent in nieuw venster) worden gehanteerd om de probleemstelling rond bedrijvigheid en innovatie in de regio aan te tonen. Verder kaan het bestuur enkele inspirerende voorbeelden aanhalen die doorheen het handboek en de online leeromgeving worden besproken.
Enkele inspirerende rapporten en voorbeelden op een rijtje om te delen binnen lokale besturen
Burgerparticipatie stimuleren
Het inschakelen van burgers en belangengroepen bij het uitvoeren van het beleid kan zorgen voor een hogere betrokkenheid bij, en dus gedragenheid van, het beleid van de lokale overheid. Open data maakt het mogelijk voor lokale overheden om burgerparticipatie te faciliteren en te stimuleren. In de kader hieronder kan je een voorbeeld lezen van een platform dat ontwikkeld is op basis van open data om het gemeenschapsgevoel in de buurt te stimuleren en samen voor een groene buurt te zorgen. Zodoende is het dus belangrijk dat je als overheid ook nadenkt over belangrijke maatschappelijke uitdagingen (zie hoofdstuk 4.2.3) en door middel van open data een oplossing ontwikkelt of faciliteert die burgerparticipatie mogelijk maakt.
Voorbeeld: “GIESS DEN KIEZ”
Daarnaast kunnen niet enkel lokale overheden of ondernemingen burgerparticipatie stimuleren maar kunnen burgers ook zelf aan de slag gaan met open data. Op deze manier kunnen burgers elkaar stimuleren om actief deel te nemen aan de gemeenschap alsook aan het beleid van de lokale overheid. In de kader “Aardbevingen in Groningen” kan je een voorbeeld lezen waarin geëngageerd burger zelf aan de slag is gegaan met open data om een toepassing te ontwikkelen die een actief probleem in de gemeenschap aanpakt. Om dit type burgerparticipatie te stimuleren zal je als lokale overheid de open data systematisch op een duidelijke manier dienen te communiceren aan burgers. Enkel op deze manier zullen zij bewust zijn van beschikbare data en vervolgens zelf op zoek gaan naar oplossingen voor maatschappelijke problemen.
Voorbeeld: AARDBEVINGEN IN GRONINGEN
Wanneer we nog een stap verder gaan, en ook externe actoren actief betrekken bij het vormgeven van het beleid, spreken we van “open government”. Meer daarover in hoofdstuk 4.5 over “stakeholdermanagement”.
Burgerparticipatie stimuleren op 2 belangrijke manieren
Kosten besparen
Een laatste, vaak onderschatte meerwaarde van een performant open data beleid is de mate waarin de betrokkenheid van de burger een meerwaarde en zelfs een kostenbesparing kan genereren. Dit vergt echter een betrokkenheid van de administratie. Zo kan bijvoorbeeld de controle van het openbaar domein deels door inwoners gebeuren, en zo een aantal controleritten overbodig maken.
Voorbeeld: GIPOD
We zullen verder zien dat veel “data stewards” nu al in continue interactie zijn met belangengroepen en individuele burgers, maar door het gebrek aan een open data beleid vormt dit dan een meerkost, eerder dan een besparingspost.
Brainstom over ALLE kosten die bespaard worden door gebruik van open data
4.3.2 Management en medewerkers engageren
Het is niet altijd eenvoudig om beleidsmakers en het management te overtuigen van deze voordelen van een open data beleid. Daarom gaan we in dit deel dieper in op hoe we de open data beleid kunnen verankeren in de organisatie. We zullen zien dat er, wanneer er een goede datamanagementstrategie werd gedefinieerd, eigenlijk niet zo veel meer dient te gebeuren.
We lichten ook toe welke activiteiten er kunnen ondernomen worden om de meerwaarde van een dergelijke open data beleid in de verf te zetten, met voorbeelden uit andere besturen.
Managers overtuigen
De belangrijkste argumenten vóór een datamanagement en een open data programma zijn te vinden in de respectievelijke visies die we opmaakten in hoofdstuk 4.2 en hoofdstuk 4.3.1 alsook in hoofdstuk 3 waarin we de redenen om met open data te engageren uiteenzetten. Desalniettemin brengt open data een aantal belangrijke cultuurveranderingen mee waardoor lokale overheden op weerstand kunnen stuiten.
Gelukkig gingen velen ons al voor en zijn er talloze kwantitatieve en kwalitatieve studies te vinden over de impact van een datamanagementstrategie. We argumenteren dat het implementeren van een open datastrategie een logisch gevolg is van een datamanagementstrategie en dus een minieme meerkost met zich meebrengt.
Het kan uiteraard helpen om een aantal inspirerende voorbeelden aan te leveren (zie kader “Artikels impact open data”).
Artikels impact open data en key take-aways om te communiceren binnen een lokaal bestuur
Medewerkers overtuigen
Medewerkers van het bestuur zullen pas overtuigd geraken van de werking van het (open)dataprogramma wanneer zij er rechtstreeks de voordelen van inzien. Daarom raden we aan om een open data beleid stap voor stap in te voeren. Het stappenplan hierna geeft aan hoe we dat precies kunnen doen.
Stappenplan: datamanagementbeleid verankeren
- Stap 1
Data stewards zijn mensen die vertrouwd zijn met bepaalde datasets en -flows, die weten wat de gevolgen zijn wanneer bepaalde data niet volledig of kwalitatief zijn. In kleine administraties zijn dit mogelijks mensen die niet erg technisch onderlegd zijn, wat hen ervan weerhoudt deze rol te willen opnemen. Toch is het belangrijk om hen te motiveren om het eigenaarschap over bepaalde datasets te willen opnemen (zie hoofdstuk 4.2.2 over data governance).
- Stap 2
Om het overzicht te bewaren over het informatielandschap en om horizontaal te kunnen werken is het belangrijk dat de verschillende data stewards elkaar regelmatig spreken. Door een data governance board in het leven te roepen vergroot het eigenaarschap dat zij voelen over “hun” datasets en kunnen zij ervaringen en pijnpunten uitwisselen. Idealiter worden zij hierbij ondersteund door een data- of enterprise architect.
- Stap 3
Vervolgens stelt het data governance board een eerste optimalisatie voor. Aangezien we ineens draagvlak willen creëren voor het open data programma selecteren we een dataset die ook voor publicatie vatbaar is. We hanteren volgende criteria:
- Vormt de data momenteel een pijnpunt?
- Zijn er meerdere data stewards of diensten afhankelijk van?
- Kan de dataset zinvol zijn voor (her)gebruikers?
(zie hoofdstuk 4.2.3)
- Stap 4
(zie verder in hoofdstuk 4.3.2 en hoofdstuk 4.3.3 over open data in bestekken en de kostprijs ervan)
Dit kunnen middelen zijn voor het vervangen of aanpassen van een systeem, een proces of een extra VTE inzet (dit zijn immers de onderdelen van een enterprise architecture).
De doelstelling van deze verandering moet steeds zijn om de kwaliteitsattributen van de dataset te verbeteren, met name Schoon, Consistent, Toegankelijk, Veilig, Gedefinieerd, Begrepen (zie hoofdstuk 4.1.1 en lesreeks 1 rond datamanagement)
- Stap 5
Een dergelijke nulmeting houdt typisch de nodige tijd of personeelsinzet in die medewerkers spenderen om taken uit te voeren die van de geselecteerde dataset afhankelijk zijn, maar dit kan even goed het aantal fout gelopen dossiers zijn, een aantal interacties, etc.
In het kader van open data kan het nuttig zijn om op dit moment een bevraging te organiseren bij externe stakeholders of om een kleine marktanalyse te doen van de sectoren waarin de data van toepassing kan zijn.
In het kader hiervan is er ook een quick scan opgesteld binnen Smart Flanders’ instrumentarium voor open data om een zelfevaluatie te doen van de maturiteit in kaart te brengen binnen (lokale) overheden.
- Stap 6
Aangezien dit een eerste stap in het (open)dataprogramma is kan deze investering gezien worden als een experiment, maar het welslagen ervan zal grotendeels bepalend zijn voor de toekomst van het programma. Het is dus belangrijk dat de verandering met grote zorg en nauwe opvolging gebeurt. Voor meer informatie over change management kan je terecht bij de extra informatie van lesreeks 3 (zie hoofdstuk 4.5 over stakeholdermanagement).
- Stap 7
Afhankelijk van de indicatoren gedefinieerd in de nulmeting kan de evaluatie van de winst meer of minder tijd vergen. Mogelijks moet de nieuwe manier van werken nog evenaarden binnen de organisatie en worden de winsten maar na verloop van tijd zichtbaar.
Het inschatten van de impact van nieuw gepubliceerde open data is nog complexer. Dit is een goed moment om die te proberen stimuleren. Meer over het stimuleren en de impact inschatten van open data in hoofdstuk 4.5 en lesreeks 5 rond stakeholdermanagement.
- Stap 8
De gerealiseerde winsten of impact vormen het belangrijkste argument om het (open)dataprogramma te verduurzamen. Het is dus van belang dit goed en breed te communiceren (zie hoofdstuk 4.5 over stakeholdermanagement).
4.3.3 Open data business modellen
Een business model beschrijft hoe waarde wordt gecreëerd en gecapteerd door een organisatie (hier, lokale overheden) door de beslissingen die gemaakt worden en de gevolgen ervan (Zeleti et al., 2016(opent in nieuw venster)). Met andere woorden, een business model is een hulpmiddel voor organisaties om de verschillende elementen van een open data project in beeld te brengen en op deze manier waardecreatie te verzekeren.
Op basis van theorie en praktijk worden er reeds verschillende business modellen voor open data voorgesteld. Onderstaande afbeelding reikt een handvat aan voor lokale overheden om een open data business model (ODBM) op te zetten. De Vrije Universiteit van Amsterdam ontwikkelde namelijk een data-gedreven innovatie canvas (DatCan)(opent in nieuw venster) die lokale overheden kan helpen om na te denken over een databeleid.
Ontwikkel een open data business model

4.3.4 (Open) data in bestekken
De relatie tussen leveranciers van technologische oplossingen enerzijds en de overheid anderzijds komt geregeld onder druk te staan. Systemen van verschillende leveranciers die dezelfde of gelijkaardige gegevens verwerken, communiceren vaak niet onderling, tot groot ongenoegen van heel wat lokale besturen. Flexibeler van leverancier veranderen blijft dan ook een complexe uitdaging. Overheden moeten zich uiteraard houden aan de wetgeving omtrent overheidsopdrachten, maar maken zich – ook onbewust – afhankelijk van derde partijen in de uitvoering of ondersteuning van hun taken. Dit noemt men de ‘vendor lock-in’: de facto vastzitten aan een leverancier, omdat de kostprijs om te veranderen te hoog is.
Dit komt doordat men zelden een onderscheid maakt tussen de data die je verzamelt of verwerkt en de toepassing die deze data ter beschikking stelt (aan de overheidsorganisatie). Data verzamelen, verwerken en ter beschikking stellen (bijvoorbeeld via een visualisatie of een rapport) wordt als één pakket aangeboden. Hierdoor ontstaan er echter problemen wanneer je als overheid van dienstenleverancier wil veranderen. Veelal zitten de data op dat moment te sterk verweven in de geboden totaaloplossing en moet men tot dure migratietrajecten overgaan. Door deze manier van werken kunnen systemen van verschillende leveranciers vaak niet met elkaar ‘praten’, wat gegevensuitwisseling tussen diensten of tussen andere overheden bemoeilijkt. Open data zijn dus ook in deze bestuurlijke context voordelig: wanneer we volgens afgesproken open standaarden data delen, bevordert dit de interoperabiliteit tussen diensten en overheden en wordt het dus makkelijker om gegevens uit te wisselen.
Het is dus zaak om in overeenkomsten met leveranciers goed te beschrijven wat je van hen verwacht ten aanzien van de data die je gaat verzamelen, beheren en ontsluiten. Deze overeenkomsten scheppen het kader waarbinnen overheid en leverancier kunnen navigeren. Voldoende duidelijkheid omtrent data levert voordelen voor alle betrokken partijen. Vandaag sluiten overheden en leveranciers nog te vaak clausules af in onduidelijke of zelfs conflicterende termen over (open) data. Het moet een reflex worden bij de aankoopdienst van elk bestuur om eenduidige (en bij voorkeur gestandaardiseerde) bepalingen omtrent (open) data op te nemen.
Dit proces start al bij de opmaak van een bestek, wanneer de aanbestedende overheid de markt om oplossingen vraagt. Idealiter worden voorbeeldclausules omtrent data opgenomen in standaardbestekken, van zo gauw een reflectie over open data van toepassing is. Het is dus ook belangrijk te investeren in voldoende bewustwording over dit topic bij de aankoopdienst, tot op het niveau van de individuele werknemer. Dit vraagt een investering in opleiding en interne communicatie, die zich weliswaar vrij rechtstreeks moet vertalen in tijds- en efficiëntiewinst op korte tot middellange termijn. Om dit proces te ondersteunen zijn er vandaag voorbeeldbepalingen beschikbaar in het Open Data Charter (zie hoofdstuk 2.3).
Wanneer je meer gaat vragen van leveranciers, is het uiteraard aannemelijk dat hier ook wat tegenover zal moeten staan. Het valt niet uit te sluiten dat gedetailleerde bepalingen omtrent (open) data in bestekken en contracten in eerste instantie een kostenverhogend effect hebben; afhankelijk van de complexiteit van de vraag valt het zelfs te verwachten. Wanneer men iets innovatiefs vraagt aan een leverancier, zijn meerkosten ook te verantwoorden. Deze kosten zullen met de loop der tijd echter afnemen, en wanneer je als lokaal bestuur op een doordachte manier met open data omspringt, zal er elders binnen de organisatie een kostenvermindering plaatsvinden. Bovendien kunnen meer samenwerking tussen overheden (zoals samenaankoop) en een nieuwe manier van aanbesteden (zoals innovatief aanbesteden) dit kostenverhogend effect opvangen.
Een andere vrees zou kunnen zijn dat je als aanbestedende overheid helemaal geen of een te beperkt aantal aanbiedingen zou krijgen, vanwege té complexe regelingen over (open) data. Dit kan men voorkomen door bijvoorbeeld een marktconsultatie uit te voeren voordat je het bestek uitschrijft. Deze manier van werken wordt vandaag onvoldoende aangewend door (lokale) overheden, maar kan onverwachte reacties vanuit de markt opvangen. Een marktconsultatie kan ertoe leiden dat de verwachtingen helder zijn, zowel bij de aanbestedende overheid als bij leveranciers. Een dergelijke aanpak zorgt ervoor dat er betere bestekken worden opgesteld en meer aangepaste oplossingen voorgesteld.
Naast een meer nauwkeurige juridische omschrijving van de verwachtingen ten aanzien van leveranciers kan een geheel andere benadering ook ondersteunend werken. In plaats van een pure klant-leverancier-relatie probeer je een vorm van partnerschap op te stellen. Er zijn een aantal werkvormen die deze situatie kunnen bevorderen. Het innovatief aanbesteden is een nieuwe manier om oplossingen te bekomen, en hanteert een ander uitgangsprincipe dan het klassiek aanbesteden. Waar men vroeger in vrij groot detail zou beschrijven aan welke functionele en vooral technische vereisten een oplossing moet voldoen, vertrekt men bij Programma Innovatieve Overheidsopdrachten (PIO)(opent in nieuw venster) eerder van een ‘uitdaging’ die in de markt gezet wordt. Hierbij heeft de aanbestedende overheid nog niet in detail voor ogen hoe een bepaalde oplossing eruit moet zien, maar beschrijft men het probleem voorhanden. De markt is dan vrij om uiteenlopende oplossingen aan te reiken. Deze aanpak komt overgewaaid uit het start-up-ecosysteem en is vrij jong, maar vindt meer en meer ingang (en juridische basis) binnen de overheid.
Voorbeelden: INNOVATIEF AANBESTEDEN
In het Smart Flanders-programma kwam men tot de conclusie dat overheden te weinig, onduidelijke of sterk verschillende bepalingen over data opnemen in overeenkomsten met leveranciers. Daarom werd een draaiboek opgesteld met voorbeeldclausules die (lokale) overheden kunnen opnemen in bestekken, concessies, contracten en andere overeenkomsten met derde partijen. Dit document is beschikbaar op Smart Flanders en mag door eenieder gebruikt worden, ter inspiratie of om rechtstreeks clausules uit over te nemen. Het document stelt een aantal algemene en technische bepalingen voor, samen met suggesties voor gunningscriteria waarmee je leveranciers kunt beoordelen op hun aanpak aangaande (open) data.
Zo zijn er bepalingen over het eigenaarschap en de toegang tot data, hoe een lokaal bestuur kan opsommen over welke data het wil beschikken en welke het als open data wil publiceren, of hoe het de aangeleverde data door een externe partij kan laten keuren. Men kan peilen naar de ervaring van een leverancier met open data en gerelateerde open standaarden (zoals Open Standaarden voor Linkende Organisaties - OSLO), en indien van toepassing kan je een aantal technische aspecten opvragen over de implementatie van linked open data. Ook de manier waarop data beschreven worden (metadatering), de publicatie van de data op de Datavindplaats, of de voorzieningen die een leverancier treft in het kader van de duurzaamheid van de voorgestelde oplossing, zijn beschikbaar in het draaiboek met de voorbeeldclausules. Met deze bepalingen streven we naar een meer uniforme aanpak van data bij aanbestedingen.
Maak gebruik van voorbeeldclausules
Ten slotte verwijzen we ook naar de website van ITS België(opent in nieuw venster), waar je specifieke voorbeeldbepalingen met betrekking tot mobiliteitsdata kan terugvinden.
4.3.5 De kostprijs van open data beperken
In het vorige deel kwamen al een aantal kwesties aan bod omtrent de kostprijs van het openen van data. Open data zijn veelal gratis om mee aan de slag te gaan als (her)gebruiker, maar als organisatie die data gaat publiceren komen er wel degelijk investerings- en onderhoudskosten bij kijken. Deze initiële investering kan je op verschillende manieren beperken, opvangen en terugverdienen.
Zoals eerder aangegeven, is het belangrijk om een open data beleid op te starten met een concrete beleidsdoelstelling voor ogen. Door data te ontsluiten in functie van een doelstelling die men hoe dan ook moet nastreven, wordt het sop al sneller de kolen waard. Bovendien is het belangrijk te vertrekken vanuit de werking van de eigen organisatie: open data kunnen immers ook een aanzienlijke rol spelen in de optimalisering van de gegevensdeling tussen verschillende diensten van de overheidsorganisatie. Door een heleboel omgevingsdata als open data ter beschikking te stellen zijn deze niet enkel raadpleegbaar voor de buitenwereld, maar uiteraard ook voor de verschillende diensten van de lokale overheid. Mits er een duidelijke communicatie is naar de medewerkers, kan een open data-aanpak er ook toe leiden dat er intern veel minder vragen om bepaalde gegevens hoeven te circuleren. Dit levert tijdswinst op en vermijdt de circulatie van verschillende lijsten met dezelfde (onvolledige) informatie.
Ook dit is op zich uiteraard niet vanzelfsprekend. Je bereikt een dergelijke manier van werken enkel wanneer ze gedragen is doorheen de overheidsorganisatie. Daarom vertaal je een open data beleid best naar concrete operationele handelingen die voor de individuele werknemer duidelijk maken hoe een bepaalde gegevensbron gedeeld kan (en mag) worden. Als dit goed wordt aangepakt, moet deze vertaling in werkprocessen slechts eenmalig gebeuren (naast de gebruikelijke bijbehorende procesevaluatie).
Investeren in open data impliceert dus ook investeren in de bewustwording over data in de hele organisatie. Hoewel het ‘smart city’-concept veel kritiek krijgt, zijn zelfs de grootste criticasters het erover eens dat een veelheid aan (betrouwbare) gegevens enkel van toenemend belang is voor de ontwikkeling, uitvoering en evaluatie van beleid. Als een investering in open data dit besef ook verder in de organisatie kan laten doordringen, komt dit de werking van de overheid enkel ten goede.
Het is in elk geval belangrijk voor elk type van overheidsorganisatie – klein of groot – om het warm water niet opnieuw uit te vinden. Ook dit principe is een belangrijke kostenbesparende maatregel. Zowel bij een aantal centrumsteden, kleinere besturen, de Vlaamse Overheid als verschillende ondersteunende initiatieven is er al veel werk verzet rond open data. Zoals eerder vermeld, is het bundelen van de krachten een belangrijke voorwaarde voor succes. Maar ook om kosten te besparen is samenwerking van cruciaal belang: samenaankoop van oplossingen is zeker een mogelijkheid die in de toekomst meer structureel toegepast kan worden. Daarnaast is het ook belangrijk om een beter zicht te krijgen op de oplossingen die de Vlaamse Overheid al ontwikkeld heeft en vandaag ter beschikking stelt van lokale besturen.
Naast de winst die open data binnen de organisatie kunnen opleveren, is het uiteraard in de eerste plaats de bedoeling dat er (her)gebruik plaatsvindt. Dit (her)gebruik kan diensten opleveren die zowel voor de overheid als voor burgers winsten kunnen opleveren.
Voorbeelden kosten terugverdienen
Om een soort (her)gebruik te laten plaatsvinden dat voor alle betrokken partijen winst oplevert, valt er wel nog steeds in de meeste voorbeelden een rol te spelen door de overheid; daar komen we in een later deel op terug.
Duurzaam open data beleid om kosten te besparen en terug te verdienen
4.3.6 Algemene tips voor een goede organisatiecultuur en -capaciteit te ontwikkelen
De kader hieronder geeft enkele algemene tips die kunnen helpen bij het uitbouwen van een goede organisatiecultuur en -capaciteit waarbij het open data beleid door iedereen gedragen wordt.
Organisatiecultuur en -capaciteit – Algemene tips
4.4 Data openstellen
Om te starten met open data is het cruciaal dat (lokale) overheden weten hoe ze open data platformen opzetten en bijgevolg data open kunnen stellen. Onderstaande paragrafen geven een overzicht van de verschillende opties om data open te stellen.
4.4.1 Werken met open data
Een basisbegrip van informatietechnologie is noodzakelijk om te begrijpen hoe open data gepubliceerd kan worden op een manier die toegankelijk en nuttig is voor (her)gebruikers. Dit deel van het handboek is dus niet bedoeld voor experten, maar biedt een concreet overzicht van de basisconcepten waar informatieverwerkers dagelijks mee te maken hebben. Een high-level begrip van deze eerder technische concepten laat het management toe om effectieve beslissingen te nemen inzake (open) datamanagement.
Machine-leesbare data
Een belangrijke voorwaarde om van open data te kunnen spreken is dat deze data “machine-leesbaar” is. In dit hoofdstuk gaan we kort in op hoe computers data opslaan, en wat “machine-leesbaar” juist betekent.
Alle data wordt binair opgeslagen, dus als een reeks van bits (0 of 1). Maar hoe kunnen we kunnen we weten wat die stroom van informatie betekent? Het antwoord is simpelweg goede afspraken. We kunnen aan de data zelf patronen toevoegen die toelaten om af te leiden hoe ze gelezen moet worden, of we kunnen naast de data een reeks van eigenschappen definiëren, die we metadata noemen (zie hiervoor naar hoofdstuk 2.1.4 en hoofdstuk 4.2.2).
Data is pas nuttig als ze machine-leesbaar is. Dat wil zeggen dat een programma de data kan inlezen en interpreteren. Alle data is in essentie een reeks binaire getallen, maar om deze leesbaar te maken zijn er afspraken nodig, zoals formaten en standaarden. We spreken over twee soorten data:
- Niet-gestructureerde data, zoals word-bestanden of een afbeelding. De data is wel leesbaar maar er kan geen onderscheid gemaakt worden tussen verschillende onderdelen of componenten.
- Gestructureerde data, waarbij er een structuur aan de data wordt toegevoegd, bijvoorbeeld bij een databank.
Om data te kunnen interpreteren is het dus belangrijk dat er afspraken zijn gemaakt over die structuur van de data. Deze afspraken noemen we formaten en standaarden. We spreken van open standaarden wanneer de standaard publiek gedocumenteerd is, zodat iedereen een applicatie kan ontwikkelen om een bepaald type data in te lezen.
In de context van open data spreken we van machine-leesbare data wanneer aan de twee voorgaande voorwaarden voldaan is:
- De data is gestructureerd
- De data volgt een open standaard
Datastructuren
Om te begrijpen op welke manier gestructureerde data wordt opgeslagen en uitgewisseld, is het belangrijk om te begrijpen welke structuren er achter deze data schuilen. We denken vaak over data als een platte lijst (een “string”) van informatie, maar er zijn verschillende manieren om de onderdelen van de lijst met elkaar in verband te brengen. Om dergelijke verbanden op te slaan en uit te wisselen moeten we op zoek gaan naar manieren om ook de structuur van de onderdelen met elkaar te formaliseren.
Een goed begrip van datastructuren zal je toelaten om in te schatten in welk formaat je best (open) data uitwisselt.
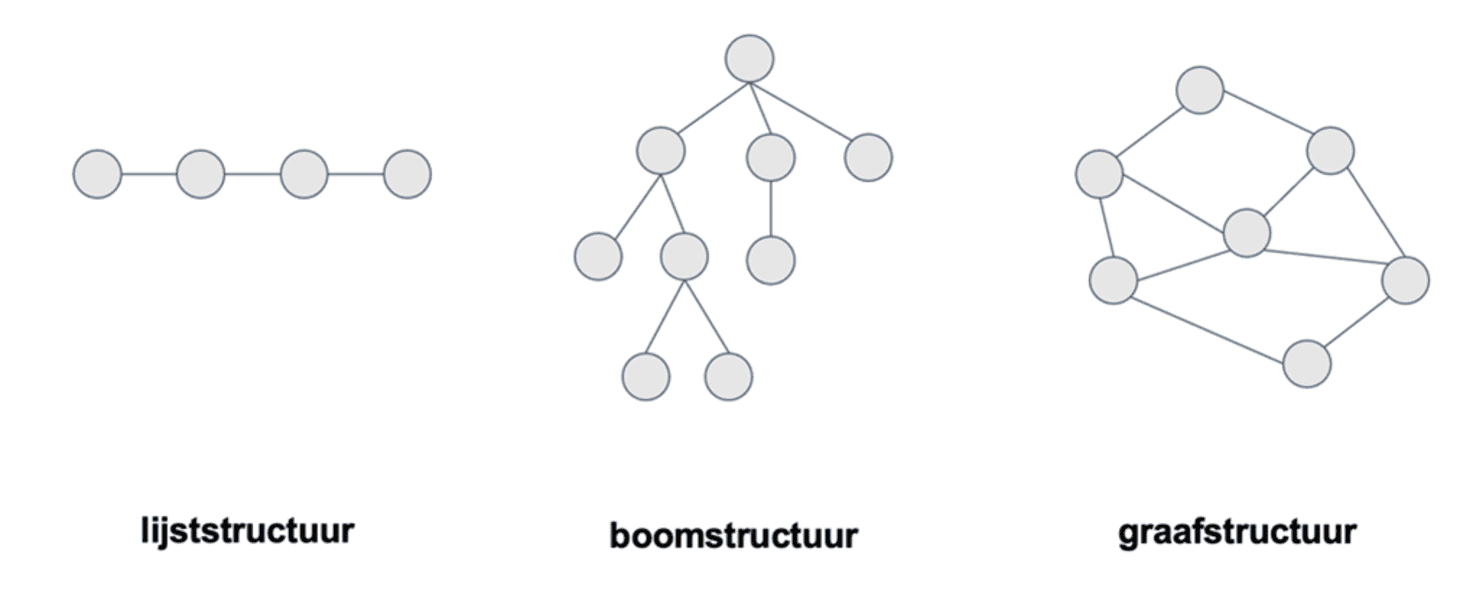
Om gestructureerde data te begrijpen is het handig om de meest courante onderliggende datastructuren te kennen (zie Figuur 15). Dit zijn:
- Lijsten: elementen of componenten volgens elkaar gewoon op maar worden op een of andere manier duidelijk gescheiden van elkaar (b.v. met een komma)
- Boomstructuren: Elke component kan 1 of meerdere subcomponenten hebben. Deze componenten worden dan “knopen” genoemd en zijn verbonden door “takken”
- Grafen: Dit is eigenlijk de meest voorkomende structuur, waarin alle componenten met elkaar verbonden kunnen zijn. Denk bijvoorbeeld aan het web.
Formaten
Typisch worden bestanden (een reeks van 0 en 1) op je computer opgeslagen op een zodanige manier dat je computer weet met welk programma dit bestand moet worden gelezen. Dat gebeurt aan de hand van de “header”, namelijk de eerste bits in het bestand.
Een “formaat” is een afspraak die aangeeft op welke manier een reeks data moet gelezen worden, en dus vaak welk type programma moet of kan worden gebruikt. Zo ken je waarschijnlijk wel het “JPG” formaat voor afbeeldingen. Voor gestructureerde data is het meest courante formaat gewoon “tekst”. Om datastructuren om te zetten in tekst, is er nog een bijkomende afspraak nodig over de structuur van de tekst, we noemen dit serialisaties. Courante serialisaties zijn:
- CSV (“comma separated values”) voor lijsten
- XML of JSON voor boomstructuren
- RDF voor grafen (zie verder onder “linked data”)
Databeschikbaarheid
Hier gaan we dieper in op hoe data beschikbaar kan worden gemaakt binnen en tussen organisatie(s). Los van de datastructuur en formaten is het immers noodzakelijk dat de data kan worden gevonden. Dat is niet altijd zo eenvoudig als het lijkt. Data kan immers op verschillende manieren worden opgeslagen. Data-uitwisseling kan pas plaatsvinden als ook de toegangswijze tot de data beschreven en duidelijk is.
We onderscheiden een aantal courante manieren om data beschikbaar te maken:
- Bestanden - Bestanden zijn zeker voor statische data nog steeds de eenvoudigste en vaak ook dus ook de effectiefste manier om data uit te wisselen. Bestanden kunnen zowel gestructureerde als niet-gestructureerde data bevatten. Wel is het belangrijk dat de data vindbaar is. Dit is niet voor alle bestandssystemen evident. Voor grote organisaties wordt er aangeraden om met een Document Management System (DMS) te worden omdat die meer mogelijkheden bieden tot metadateren en zoeken.
- Databanken - Databanken - ook wel databases genaamd - verwijzen naar systemen die data verzamelen, organiseren en linken aan elkaar. Op deze manier kan de open data eenvoudig worden geraadpleegd door (potentiële) (her)gebruikers. De mogelijke nadelen die verbonden zijn aan het gebruik van databases omvat de aankoopkosten alsook de personeelskosten voor aanmaak en onderhoud van de database. Daarnaast dient het personeel de nodige kennis te bezitten. In dit kader zijn mogelijks opleidingen voor overheidspersoneel wenselijk.
- APIs (application programming interfaces) - Door middel van API’s (Application Programming Interfaces) kunnen verschillende “services” met elkaar communiceren. Deze services kunnen toegang geven tot gestructureerde data op basis van bepaalde aanvragen van de externe partij, zij het mens of machine. Daarenboven kunnen zij intern nog een aantal operaties uitvoeren om die data te genereren, te selecteren, etc. API’s zijn de aangewezen publicatievorm bij data die dus nog wat voorverwerking vereist, of b.v. in het geval van real-time data.
- Het Web - Elk van deze publicatievormen kan worden toegepast binnen een intern netwerk of op het internet. Echter, enkel in dat laatste geval kunnen we spreken van open data. Het web heeft als bijkomend voordeel dat data eenvoudig gelinkt kan worden.
Elk van deze manieren hebben hun eigen voor- en nadelen. Het is dus niet altijd wenselijk om alle data van de organisatie op dezelfde manier beschikbaar te maken. De beste manier hangt af van de aard van de data en het doel van de gebruiker.
Werken met open data
Het antwoord op deze vraag is niet eenduidig: Het hangt af van de visie van het lokale bestuur, de interne capaciteit, maar ook hoe het bestuur via de data met (her)gebruikers in contact wil komen. (Zie ook lesreeks 5 van de online leeromgeving over aanschaf van technologie.)
Neem bijvoorbeeld een ontwikkelaar die een applicatie wil bouwen om op te zoeken hoeveel energie de overheidsgebouwen in een gemeente verbruiken. Als die ontwikkelaar wil nagaan of er al nuttige datasets beschikbaar zijn, waar kan die dan terecht? Veelal is Google of een vergelijkbare zoekmachine op het web de plaats om te starten. Met de juiste zoektermen en afhankelijk van de manier waarop de websites beschreven zijn, zal dit een aantal bruikbare resultaten opleveren, zoals de open data van de VREG, Eandis en het CRAB.
Wanneer de ontwikkelaar echter meer gestructureerd te werk wil gaan en bijvoorbeeld zicht wil krijgen op de beschikbare data binnen een breed thema zoals klimaat, kan een open data portaal nuttig zijn. Dit is een online omgeving waarin je een hele hoop datasets kunt doorzoeken en opvragen. Je kan bijvoorbeeld ook volgens thema of op basis van de publicerende organisatie door de verschillende datasets bladeren. Net als bij de zoekmachine van Google hoeft dit niet te betekenen dat datasets gecentraliseerd moeten worden in de letterlijke betekenis van het woord. Door gestructureerde metadata (data over data) toe te voegen, kunnen verschillende organisaties data publiceren op hun eigen websites en worden deze toch vindbaar op een portaal.
Is een dergelijk portaal de investering waard voor elke stad of gemeente? Er zijn hierbij twee soorten ‘publicerende’ instanties:
- Individuele organisaties die hun data publiceren als open data, bijv. via de eigen website;
- Overkoepelende en integrerende open data portalen op verschillende bestuursniveaus, bv. Vlaams of Europees open dataportaal.
Voor individuele organisaties die open data willen publiceren, is het niet altijd nodig om in een uitgebreid portaal te voorzien. Als de metadata gestructureerd en gestandaardiseerd beschreven zijn, worden de data vindbaar in andere open dataportalen én via andere zoekmachines. Lokale, kleinere besturen kunnen ervoor kiezen om een open datapagina op hun website aan te maken, terwijl grotere steden of organisaties met meer slagkracht (en meer data) ervoor kunnen opteren om een eigen portaal aan hun medewerkers, burgers en bedrijven aan te bieden. In dat geval gaat het om een bewuste keuze die ook een kostprijs met zich zal meebrengen voor de implementatie en het onderhoud, maar een dergelijk portaal kan ook een belangrijk communicatiemiddel zijn. Het kan dienen als ‘visitekaartje’ voor het open data of smart city beleid van de stad of een rol vervullen als dialoogplatform.
Er zijn vandaag al behoorlijk wat voorbeelden van overkoepelende open data portalen. Er is een Europees dataportaal, maar ook een federaal, Waals en Vlaams, een voor het Brussels Hoofdstedelijk Gewest en een ander voor de stad Brussel; de stad Antwerpen en de stad Gent hebben een eigen portaal… (zie kader voor een illustratief overzicht). Een dergelijke wildgroei aan portalen is uiteraard nefast voor de vindbaarheid van data, want waar moet men beginnen zoeken? Ook hier is dus een gestructureerde en gestandaardiseerde metadatering van cruciaal belang. Wanneer een publicerende organisatie de correcte metadatering toepast, worden data vindbaar in verschillende overkoepelende portalen en wordt de kans op (her)gebruik van de data dus ook aanzienlijk vergroot.
De metadata vormen eigenlijk de beschrijving van een dataset. Ze kunnen informatie bevatten over de oorsprong van de data, de periode die ze beschrijven, het formaat waarin ze aangeboden worden, de beheerder van de data, de locatie die ze beschrijven enzovoort. Ook metadata worden op hun beurt het best op een gestructureerde en gestandaardiseerde manier bijgehouden en gepubliceerd. Dit maakt het mogelijk om snel en automatisch de informatie over data met elkaar te vergelijken en eventueel datasets te koppelen aan elkaar. Het zorgt er ook voor dat datasets makkelijk terug te vinden zijn, bijvoorbeeld in een portaal. Momenteel wordt de DCAT-standaard(opent in nieuw venster) aanbevolen. Van zodra je deze metadateringsstandaard gebruikt om een dataset te beschrijven en deze op het web publiceert, zal de dataset niet alleen vindbaar zijn op de Datavindplaats, maar ook op het federale, het Europese en eventuele andere portalen.
Illustratief overzicht van open data portalen
Verder hebben verschillende lokale besturen eigen lokale dataportalen opgezet. Ze doen dit omwille van het actief streven naar transparantie en om (lokale) innovatie te stimuleren. Andere besturen die aan open data publicatie doen, doen dit via overkoepelende platformen. Deze werden ontwikkeld met het oog op schaalvergroting, omwille van efficiëntie en de toevloed aan realtime data.
Beide manieren van werken hebben als voordeel dat ze capaciteitsopbouw (kennis, ervaring, methodische vaardigheden) in de hand werken. Een van de uitdagingen die open data publicatie en platformdenken met zich meebrengen, is echter het feit dat (her)gebruikers te weten moeten komen waar data te vinden is. Men kan dan dataportalen koppelen of integreren in een algemeen portaal of een vindplaats die vlot doorzoekbaar is en waar (her)gebruikers data van verschillende publishers kunnen terugvinden.
Drie manieren om data te publiceren
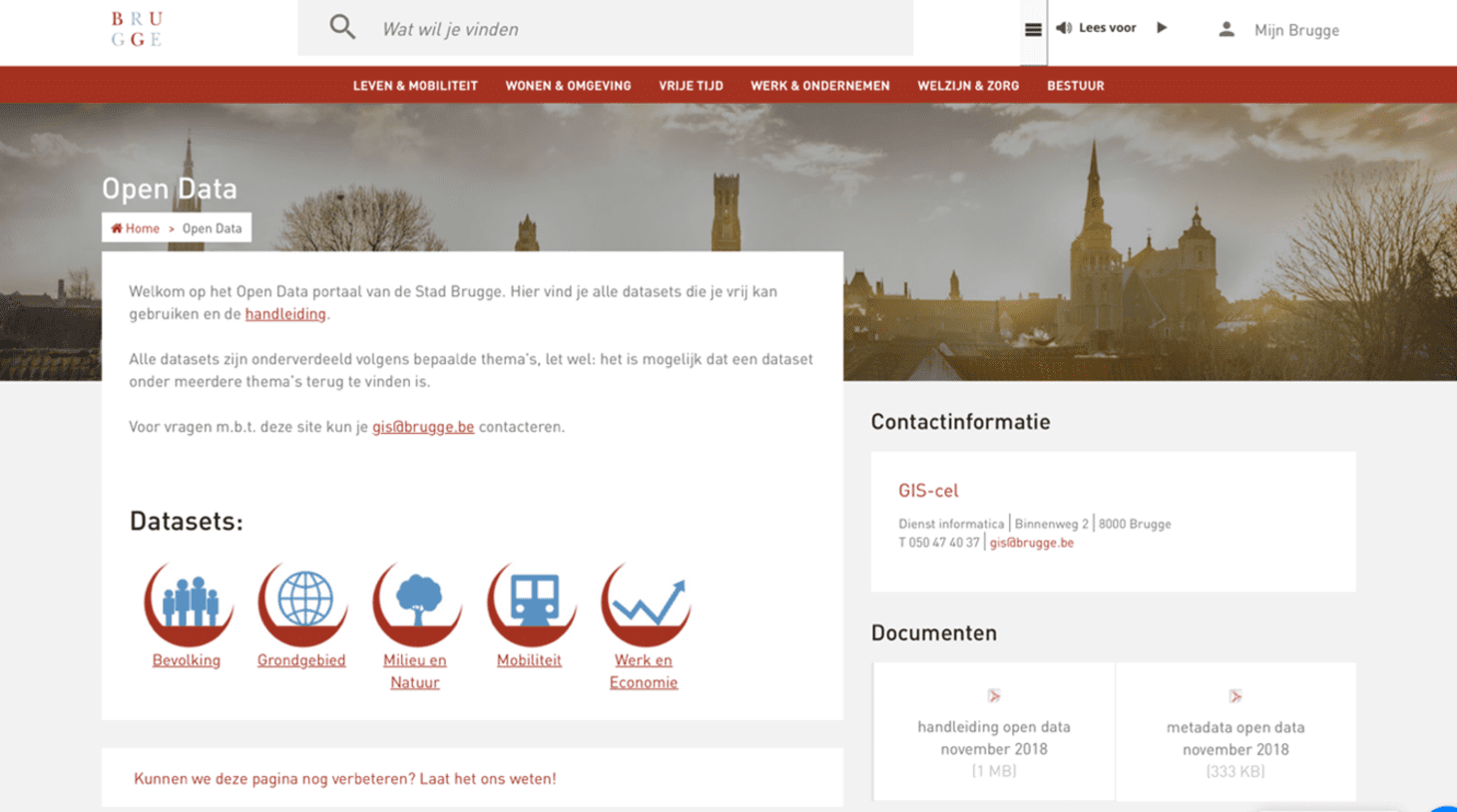
Voorbeelden: open datapagina, eigen webpagina via overkoepeld dataportaal, eigen dataportaal
Voorbeelden van lokale besturen die eerder voor een open datapagina kiezen waar datasets gedownload kunnen worden, zijn Brugge (https://www.brugge.be/opendata(opent in nieuw venster) – zie afbeelding onder) of Oostende (https://www.oostende.be/opendata.aspx(opent in nieuw venster)).
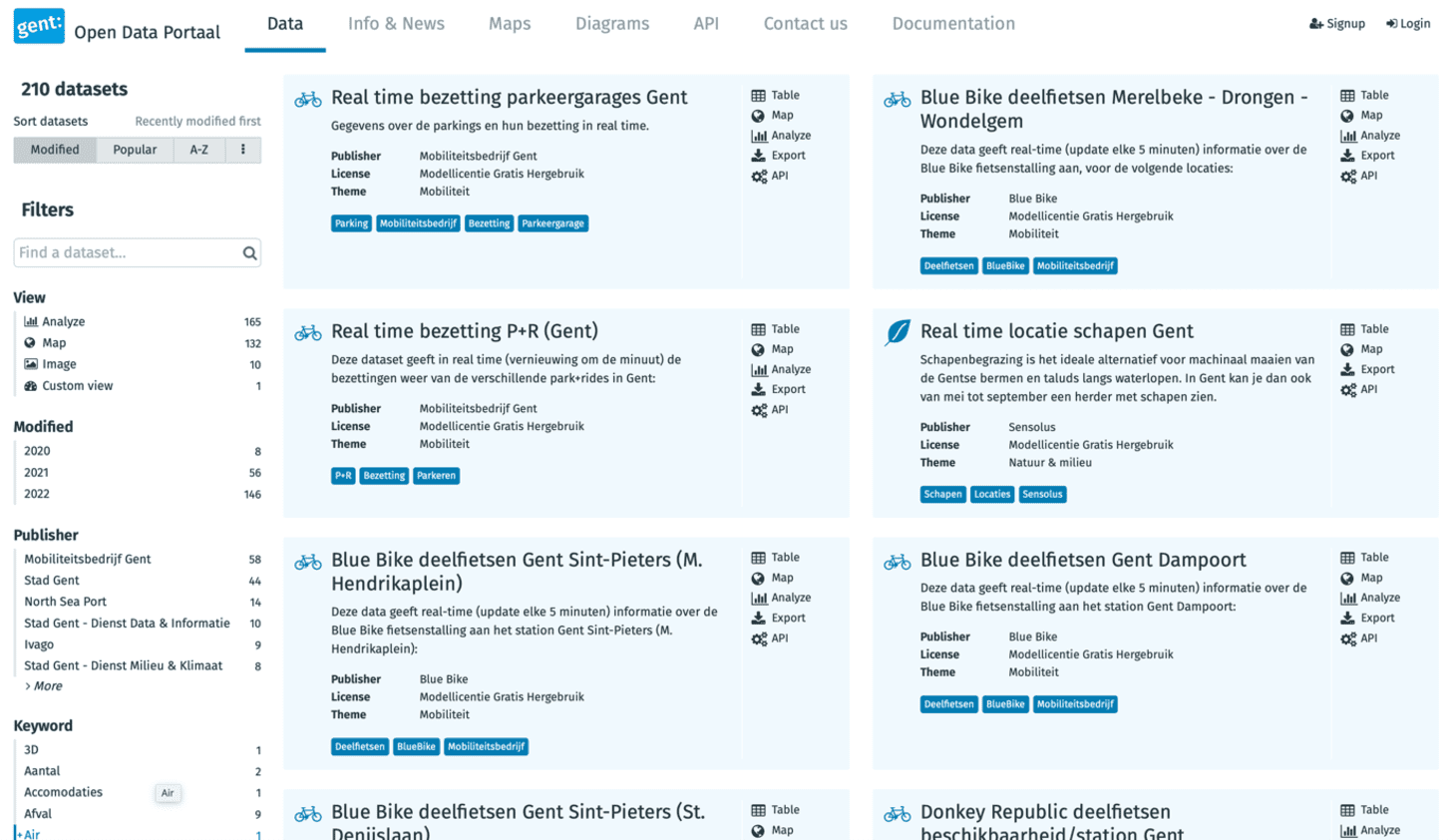
De Stad Gent en Antwerpen hebben hun eigen data portaal (respectievelijk, https://data.stad.gent/(opent in nieuw venster) (zie afbeelding onder) en https://opendata.antwerpen.be/(opent in nieuw venster)).
De stad Kortrijk publiceert vandaag open data op haar eigen website (https://www.kortrijk.be/data(opent in nieuw venster)).
4.4.3 Algemene tips voor beschikbaar maken van open data
Om jou als lokale overheid op weg te helpen met het beschikbaar stellen van open data voor (her)gebruik, lijsten we nog enkele algemene tips op in deze kader.
Data openstellen – Algemene tips
4.5 Stakeholdermanagement: engageren en (her)gebruik stimuleren
Open data is bij uitstek een middel om verschillende actoren met een gemeenschappelijke uitdaging te verbinden, en het is net uit deze interactie dat de mooiste innovaties of toepassingen voortvloeien. Zodoende licht deze categorie toe hoe (lokale) overheden alle betrokken stakeholders kunnen engageren om (her)gebruik te stimuleren en zo meerwaarde te creëren voor iedereen.
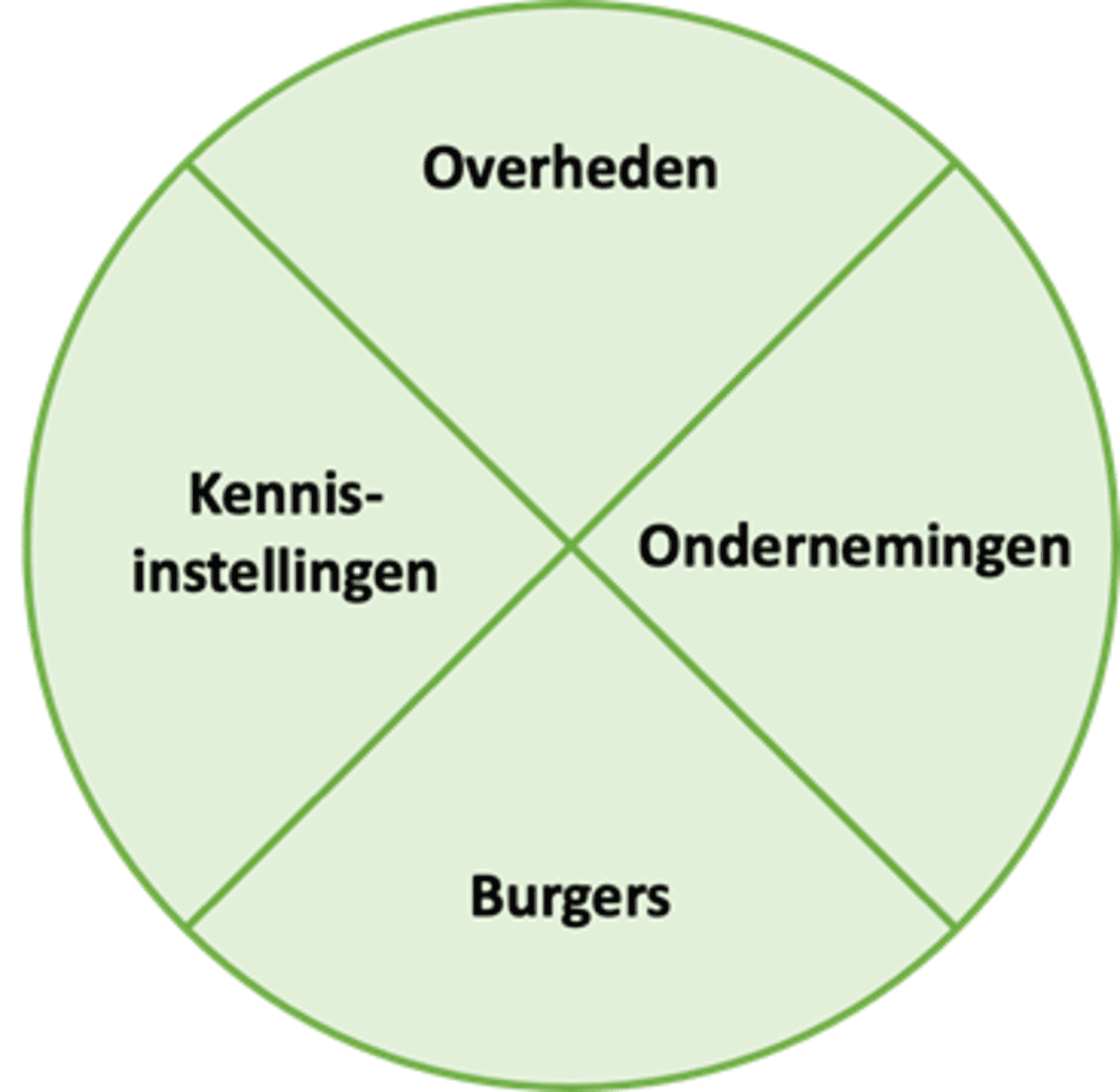
4.5.1 Stakeholders in quadruple helix engageren
Om een inzicht te geven rond hoe we deze stakeholders kunnen identificeren en benaderen, en hoe zij moet bepaalde open datasets aan de slag gaan, hanteren we het quadruple helix model (zie afbeelding).
Onder de quadruple helix verstaan we de interactie tussen spelers uit 4 kwadranten: overheden, bedrijven, kennisinstellingen en burgers. Of m.a.w. de publieke, private en academische sectoren, aangevuld met de individuen.
Quadruple Helix: Luchtkwaliteit

Om het succes van open data te garanderen en dus de investering te laten renderen dienen (lokale) overheden deze verschillende stakeholders in het quadruple helix model te engageren. Dit kunnen ze doen door de meerwaarde van open data voor deze verschillende stakeholders in de verf te zetten. Hierbij kunnen (lokale) overheden – onder andere – focussen op: economische en maatschappelijke meerwaarde.
Economische meerwaarde
In dit hoofdstuk willen we een aantal concrete, lokale, voorbeelden toelichten van hoe open data voor een economische meerwaarde kan zorgen. Elk van de actoren binnen de quadruple helix kan economische meerwaarde ondervinden van open data.
Zo kan de overheid b.v. besparen door een deel van de dienstverlening te laten gebeuren door andere actoren via open data. Verder stimuleert open data de vrije markt en vergroot zij de concurrentiekracht. Volgens de Europese Commissie is data “niet-rivaliserend goed” en kan de stroomlijning van de datamarkt tegen 2028 een extra 270 miljard aan bruto nationaal product opleveren voor de lidstaten.
Binnen kennisinstellingen of de academische sector zorgt een vlotte doorstroom van data voor een enorme kostenbesparing, vooral wanneer niet enkel de onderzoeksresultaten maar ook de ruwe data verzameld in het kader van een onderzoek worden vrijgegeven. Door het (her)gebruiken van ruwe onderzoeksdata (zoals metingen en analyses) kan data-acquisitie veel efficiënter georganiseerd worden. Dit wordt benoemen we als open science. Open access is de beweging die streeft naar de open publicatie van onderzoeksresultaten zoals wetenschappelijke papers. Die is nu veelal in handen van uitgevers die vaak een monopoliepositie hebben.
Binnen ondernemingen in de private sector en de industrie kan open data het mogelijk maken om volledig nieuwe business modellen en innovaties te ontwikkelen. Meer hierover in lesreeks 7, met name onder de Europese Data Act en Data Governance Act. Verder kunnen bedrijven kunnen meerwaarde creëren bovenop data die door publieke spelers worden verzameld. De uitdagingen hierbij zijn echter dat:
- De kwaliteit en beschikbaarheid van open data niet altijd gegarandeerd is.
- Bedrijven uiteraard vaak de data die zij verzamelen en verrijken als strategische asset zien en er dus belang bij hebben om deze in exclusief beheer te houden.
Voor burgers creëert open data enerzijds onrechtstreeks economische meerwaarde doordat de verhoogde competitie en dus betere en goedkopere diensten, maar anderzijds ook directe meerwaarde doordat zij beter geïnformeerd worden en dus hun consumptie- en investeringsbeslissingen kunnen optimaliseren.
Voorbeeld: GENTSE FEESTEN
Communiceer en onderbouw de economische meerwaarde naar alle belanghebbende
Maatschappelijke meerwaarde
De meerwaarde van open data beperkt zich niet tot het economische. Er zijn talloze voorbeelden van hoe open data heeft geleid tot maatschappelijke meerwaarde heeft geleid. Ruwweg kan je deze opdelen in de volgende categorieën:
- Een transparante overheid leidt tot een groter vertrouwen en een maatschappelijk debat.
- Open data creëert de mogelijkheid voor verschillende partijen om bepaalde maatschappelijke problemen beter in kaart te brengen
- Een transparante overheid laat verder toe dat burgerinitiatieven zich beter kunnen organiseren en verhoogt de mogelijkheid tot burgerparticipatie.
Deze voordelen van open data werden in hoofdstuk 3 reeds uitgebreid besproken samen met andere voordelen waaronder ecologische, sociale en politieke voordelen.
Voorbeeld: MISSING MAPS
Communiceer de maatschappelijke meerwaarde op interactieve manieren
4.5.2 (Her)gebruik stimuleren
Open data realiseert uiteraard pas meerwaarde wanneer deze (her)gebruikt wordt. Dit gebeurt niet altijd vanzelf. Zodoende formuleren we enkele voorbeelden en tips om (her)gebruik te stimuleren.
Voorbeelden uit binnen- en buitenland leren namelijk dat open data publiceren niet automatisch leidt tot een verrijking of (her)gebruik van de data. Veel heeft te maken met een aantal eerder aangehaalde kwesties: beschikbaarheid, vindbaarheid, fragmentatie, bruikbaarheid, betrouwbaarheid enzovoort. Open data dragen in die zin een ‘de-kip-of-het-ei’-probleem in zich: er moeten voldoende data beschikbaar zijn voordat een (her)gebruiker ermee aan de slag zal gaan, en overheden zijn pas bereid data te openen als er een duidelijke vraag naar is.
We bevinden ons momenteel in een overgangsfase, waarin de meerwaarde om data open te stellen niet altijd duidelijk is, zeker voor het lokale niveau. Toch ligt ook hier een opportuniteit voor innovatie, namelijk in de ondersteuning van open data publicatie en de verrijking van data door een hogere overheid of door derde partijen. Technische oplossingen waardoor medewerkers van de administratie makkelijker data kunnen invoeren, verrijken of publiceren, bieden vandaag zeker een meerwaarde. Dergelijke oplossingen kunnen een deel van de achterliggende complexiteit verbergen voor de eindgebruiker en er tegelijkertijd voor zorgen dat er meer open data beschikbaar worden.
Voorbeeld: LBLOD
Er liggen dus zeker nog opportuniteiten in de verdere ondersteuning van de aanmaak, aanvulling, verwerking en uiteindelijke ontsluiting van uiteenlopende soorten data. Hoewel deze mogelijkheden vaak commercieel van aard zullen zijn, kunnen ze ook voor het lokale bestuur een tijds- en efficiëntiewinst opleveren, en kunnen ze de steden en gemeenten ontzorgen op het vlak van data-ontsluiting. Om te verzekeren dat dit op een correcte en gestandaardiseerde manier gebeurt, verwijzen we naar ‘(Open) data in bestekken’ in hoofdstuk 4.3.4.
Voorbeeld: OPENBAAR DOMEIN
Enkel data openen betekent dus niet automatisch dat er nieuwe of innovatieve toepassingen mee gebouwd zullen worden. Dit wil niet zeggen dat open data onvoldoende potentieel hebben: er zijn voorbeelden in binnen- en buitenland waarbij open data aantoonbaar tot nieuwe toepassingen en zelfs geheel nieuwe ecosystemen van (her)gebruikers geleid hebben.
Wat is er dan nodig om te vermijden dat het openen van data een maat voor niets blijft en enkel kosten oplevert voor de publicerende organisatie? Hoe scheppen we een kader waardoor er effectief (her)gebruik van de data plaatsvindt?
Een van de eerste cruciale voorwaarden is communicatie. Vanzelfsprekend moet de buitenwereld ervan op de hoogte zijn dat je als overheidsorganisatie data publiceert en waar deze dan te vinden zijn. Manieren om hieraan tegemoet te komen zijn een informatiecampagne, infomomenten en aanwezigheid op relevante events. Een voorbeeld hiervan is de sensibiliseringscampagne van de Vlaamse overheid voor (her)gebruik van overheidsinformatie en open data.
De bekendmaking van de open data is één aspect, maar in tweede instantie moet je ook meegeven in welke context de data tot stand kwamen en hoe derden ze eventueel kunnen gebruiken. De beleidsmatige uitdaging waar men als overheid voor staat, moet duidelijk zijn. Dit vraagt soms enige durf en transparantie. Deze aanpak geeft prospectieve (her)gebruikers meer inzage in het potentieel van de data en kan hen inspireren om met de data een oplossing te creëren die voor alle betrokken partijen winst oplevert.
Een derde succesvoorwaarde is dan documentatie. Een ontwikkelaar moet begrijpen hoe hij met de data aan de slag kan gaan, wie hij eventueel kan contacteren voor meer informatie, in welk kader de data tot stand gekomen zijn, welke technische of andere beperkingen er eventueel op de data van toepassing zijn enzovoort. De data en de manieren om ermee aan de slag te gaan, zijn dus best goed gedocumenteerd om een makkelijk (her)gebruik toe te laten.
Om te verzekeren dat er (her)gebruik van de open data plaatsvindt, kan je als overheidsorganisatie nog een stap verder gaan en (al dan niet met een externe, adviserende partner) een meer faciliterende rol opnemen. Dit kan zich in de praktijk vertalen naar werksessies of andere ontmoetingen met potentiële (her)gebruikers om (1) te communiceren welke open data er beschikbaar zijn en wat de tijdslijn is voor de publicatie van nieuwe datasets, en (2) om een beter zicht te krijgen op welke verwachtingen er leven bij eventuele (her)gebruikers ten aanzien van de overheid over beschikbare data. Het is dus ook van belang dat de instantie die data publiceert in dialoog kan gaan met potentiële (her)gebruikers om een betere inschatting van haar investeringen in open data te kunnen maken. Je dient dan voor ogen te houden dat je voor dergelijke informatiemomenten voldoende brede uitnodigingen verstuurt, om enerzijds een breed publiek te bereiken en anderzijds te vermijden dat je bepaalde partijen zou bevoordelen. Dit kan je ook vermijden door een externe, adviserende partij in te schakelen om dergelijke momenten te organiseren.
Een belangrijke kwestie die hier in beeld komt, is in essentie een kerntakendebat: hoe ver moet de rol van de overheid hier gaan? Bovendien is het ook niet voor elk lokaal bestuur haalbaar een dergelijke outreach op te zetten. Men kan perfect beargumenteren dat enkel de ontsluiting van de data een opdracht van de overheid is (zoals in Vlaanderen verankerd in het Bestuursdecreet en dat het daarbij ophoudt. Elk bestuur kiest uiteraard zelf in welke mate zij kunnen of willen investeren in een open data programma. Echter, vaak kunnen kleine investeringen grote veranderingen teweeg brengen. Een goede samenwerking met de Vlaamse en federale overheid kan schaalvoordelen mogelijk maken. Ons advies is om minstens het debat aan te gaan met lokale stakeholders. Het data-debat beperkt zich overigens niet meer tot open data. De Europese Data Act en Data Governance Act maken het mogelijk om met (lokale) data-eigenaars in debat te gaan over hoe er Data Spaces gecreëerd kunnen worden die economische meerwaarde creëren, ook binnen een betalend model.
Samenvattend is het onder de huidige zienswijze van belang om alle belanghebbende actoren zoals bedrijven, andere overheden, kennisinstellingen, burgers en middenveldorganisaties te consulteren bij het openen van data. Door infomomenten te organiseren krijg je een beter beeld op de verwachtingen en doelstellingen van de verschillende actoren. Zo kan je meer gericht aan de slag gaan bij de ontsluiting van data, de planning van de publicatie van andere data en – fundamenteel – ervoor zorgen dat je als overheid relevante data openstelt die tot interessant en innovatief (her)gebruik leiden.
Hoe stakeholders en (her)gebruik engageren?
4.5.3 Algemene tips voor het managen van stakeholders
In bijgevoegde kader geven we nog enkele algemene tips mee die belangrijk kunnen zijn bij het managen en engageren van alle stakeholders van jouw open data beleid.
Stakeholdermanagement – Algemene tips
Onderteken en ratificeer het Open Data Charter
4.6.2 Andere relevante regelgeving
Openbaarheid van Bestuur
Een van de belangrijkste basisbeginselen die aan de grond liggen van open data is de openbaarheid van bestuur. Europa kent een lange traditie hierin, de eerste wet die dit beginsel bestendigde is de “Freedom of the Press Act” die werd ingevoerd in Zweden in 1766.
Openbaarheid van bestuur betekent dat kiezers in staat moeten zijn om de werking van hun overheid te volgen en om na te gaan waarom bepaalde beslissingen worden genomen. Dit staat nog ver af van wat we tegenwoordig “open data” noemen. Wetgeving rond openbaarheid van bestuur houdt voornamelijk in dat kiezers bestuursdocumenten moeten kunnen inzien wanneer zij daarom vragen. Een overzicht(opent in nieuw venster) van de geldende wetgeving hierrond vinden we op de website van de federale overheid.
Het is belangrijk om te weten dat elk document, maar ook elke dataset, die de overheid verwerkt, juridisch gezien wordt als een bestuursdocument en dus gevat wordt onder de wet op openbaarheid van bestuur. Om van open data te kunnen spreken volstaat het echter niet om de openbaarheid van bestuur te implementeren. En dat om twee redenen:
- Openbaarheid is reactief: de burger moet de toegang tot bestuursdocumenten aanvragen
- Openbaarheid is selectief: de burger moet specifieke bestuursdocumenten opvragen
De aldus verkregen bestuursdocumenten zijn zelden machine-leesbaar of actueel
(Her)gebruik van overheidsinformatie
De term “hergebruik” slaat op het gebruiken van publiek beschikbare overheidsgegevens voor andere doelen dan waarvoor die gegevens werden ingezameld. Ook dit concept is verankerd in de wetgeving. Op Europees niveau werd in 2003 de “PSI (Public Sector Information) Directieve” geïntroduceerd die stelt dat alle gegevens die door publieke instanties (en dus ook in opdracht van publieke instanties!) moeten worden gepubliceerd als open data, tenzij zij persoonsgegevens bevatten of een risico kunnen vormen voor de staatsveiligheid.
Die Europese directieve heet tegenwoordig de “Open Data Directive” en is door alle lidstaten geïmplementeerd in de nationale wetgeving. In Vlaanderen zijn deze principes inmiddels opgenomen in het bestuursdecreet(opent in nieuw venster) van 8 december 2018, met name onder hoofdstuk 4. Merk op dat dit decreet het gebruik van bestuursdocumenten binnen de overheidsinstaties (uitsluitend voor andere doeleinden binnen de publieke taak) en de uitwisseling van bestuursdocumenten tussen overheidsinstanties (uitstuiend met het oog op de vervulling van hun publieke taak) uitsluit van de term ‘hergebruik’. Bijgevolg verwijzen we in dit handboek steeds naar hergebruik door derden en gebruik door overheidsinstanties als ‘(her)gebruik’.
GDPR
De General Data Protection Regulation (GDPR) of in het Nederlands de Algemene Verordening Gegevensbescherming is een Europese verordening die werd ingevoerd op 25 mei 2018 en die als doel heeft om elke organisatie die persoonsgegevens verwerkt aan een hoge standaard te houden inzake de veiligheid van die gegevens. Aangezien het een verordening betreft is die onmiddellijk geldig voor alle organisaties in de lidstaten zonder dat daar nog nationale of regionale wetgeving hoeft te worden vooropgesteld.
Wanneer je als organisatie een gedegen datamanagementbeleid hebt ingevoerd, zou de implementatie van de GDPR niet zoveel voeten in de aarde moeten hebben. We argumenteren dat gegevensbescherming en open data twee zijden zijn van dezelfde medaille.
De GDPR gaat uit van 6 basisprincipes:
- Rechtmatigheid, behoorlijkheid en transparantie: elke verwerking gebeurt in lijn met de geldende wetgeving
- Doelbinding (finaliteit en proportionaliteit): Persoonsgegevens mogen enkel verzameld worden voor een specifiek doel en proportioneel daarmee
- Minimale gegevensverwerking: Enkel die gegevens mogen verwerkt worden die noodzakelijk zijn om het doel te bereiken
- Juistheid: De gegevens moeten juist zijn en het moet mogelijk zijn verbetering aan te vragen
- Opslagbeperking: De opslag van gegevens moet beperkt worden in de tijd.
- Vertrouwelijkheid en integriteit: De gegevens mogen niet gedeeld worden met andere partijen of van vorm worden veranderd
Als organisatie moet je een aantal maatregelen nemen:
- Een functionaris gegevensbescherming of een data protection officer (DPO) aanstellen die rechtstreeks rapporteert aan de CEO.
- Opstellen en bijhouden van een verwerkingsregister waarin alle verwerkingen en hun rechtsgrond per bron van persoonsgegevens worden bijgehouden
- Verwerkingsovereenkomsten afsluiten met alle derde partijen die voor de organisatie persoonsgegevens verwerken.
Data en Data Governance Act
De Data Governance Act is in eerste instantie bedoeld als wettelijke basis voor het organiseren van datadeling in sectorale dataruimten. Dit initiatief is complementair aan de General Data Protection Regulation (GDPR)(opent in nieuw venster) en de hernieuwde PSI directive (Open Data (cfr. Open Data Directive) en Hergebruik van Overheidsinformatierichtlijn). Het streeft naar het verder openstellen van overheidsdata en biedt een kader voor het delen van data en het verdere gebruik van data voor onderzoek of andere altruïstische bedoelingen.
De voorgestelde verordening omvat drie hoofdgebieden:
- De eerste zijn beschermde gegevens van de publieke sector. Het algemeen beschikbaar maken van dergelijke gegevens kan een krachtig instrument zijn om groei te stimuleren.
- Het 2de gebied is dat van data-intermediatiediensten. Dit zijn neutrale “makelaars” die de gegevens an sich niet voor hun eigen voordeel mogen gebruiken of (zoals een eigen product te ontwikkelen) maar instaan voor kwalitatieve verspreiding.
- Het 3de gebied heeft betrekking op ‘data-altruïsme’, dat wil zeggen de voorwaarden waaronder burgers of de particuliere sector vrijwillig en gratis hun gegevens kunnen delen met non-profit organisaties voor het algemeen belang.
De Europese Commissie legt in de Data Act uit dat data een niet-rivaliserend goed is, wat inhoudt dat het keer op keer kan worden geconsumeerd zonder dat de kwaliteit wordt aangetast of dat het aanbod opraakt. Ze richt zich zowel tot bedrijven als particulieren, en wil dataportabiliteit verhogen, met name voor Internet of Things (IoT) apparaten. Dit zodat je, wanneer je een product aanschaft dat data genereert, (op zijn minst mede-) eigenaar wordt van die data, en die kan gebruiken om nieuwe waarde te genereren.
De Data Act is nog volop in opmaak, maar de Europese Commissie maakt zich sterk dat het beschikbaar maken van data tegen 2028 270 miljard euro extra BBP kan genereren in de eurozone.
Auteursrecht
Het auteursrecht beschermt de originele creaties van de geest: beeldhouwwerken, literaire en wetenschappelijke teksten, scenario’s, schilderijen, foto’s, filmwerken, voordrachten, … Deze rechten verwerft de auteur automatisch en zijn exclusief. Je mag deze werken dus niet delen zonder toestemming. In sommige gevallen kan dit ook van toepassing zijn op een dataset, indien daar een creatief proces aan vooraf is gegaan.
Om anderen toe te laten de zo beschermde werken te gebruiken of te verdelen moet het auteursrecht worden overgedragen, of moet de auteur er afstand van doen (dan wordt het werk “publiek domein”). Let wel, zelf als de auteur de auteursrechten heeft overgedragen, dan nog heeft hij of zij “morele” rechten of “persoonlijkheidsrechten”.
Belangrijke regelgeving om op te nemen in juridisch kader
4.6.3 Algemene tips voor een goed juridisch kader
Om jou als lokale overheid op weg te helpen met het uitwerken van een goed juridisch kader voor jouw open data beleid, lijsten we nog enkele algemene tips op in deze kader.
Juridisch kader – Algemene tips
Bij het doorlopen van dit stappenplan voor een concrete implementatie van open data door jouw lokaal bestuur zijn er enkele belangrijke aandachtspunten en aanbevelingen uitgelicht om in je achterhoofd te houden:
- Bouw aan een (open)databeleid dat ambitie en focus in zich draagt en dat de koppeling maakt met wat er vandaag al gebeurt (bijvoorbeeld het Open Data Charter).
- Bekrachtig het Open Data Charter binnen het bestuur.
- Vertaal dit beleid in een actieplan met concrete stappen, deadlines en verantwoordelijken.
- Ontwikkel en documenteer ook interne procedures om data te ontsluiten.
- Werk vanuit een concrete beleidsuitdaging; dit creëert inherent meer draagvlak dan ‘openen om te openen’.
- Om technische knowhow op te bouwen kan het weliswaar interessant zijn om bij wijze van experiment ‘makkelijke’ datasets online te plaatsen, bijvoorbeeld statische data die in spreadsheets gestructureerd zijn. De opdrachten op de online leeromgeving helpen je hierbij alvast op weg. Verder zou je dit ook kunnen ondernemen in het kader van een hackathon.
- Voorzie in de training van medewerkers over datahygiëne, metadatering, standaarden, procedures voor ontsluiting enzovoort.
- Duid binnen verschillende diensten data stewards aan met duidelijke verantwoordelijkheden omtrent de interne datahuishouding en de publicatie van open data.
- Ga in dialoog met experts buiten de organisatie, om beleidsmatige uitdagingen te ontdekken of om ideeën te identificeren die leven bij burgers, middenveldorganisaties of bedrijven. Zo identificeer je ook de technische uitdagingen die open data met zich meebrengen.
- Maak maximaal gebruik van de gangbare standaarden om data te delen tussen overheden.
- Ga de dialoog over open data aan met leveranciers of aanbieders van technologische oplossingen en maak gebruik van dezelfde bepalingen omtrent open data in bestekken, aanbestedingen, concessies, contracten enzovoort.
Omarm semantische interoperabiliteit: een gemeenschappelijk begrippenkader laat toe dat machines hetzelfde begrijpen onder bepaalde concepten. Door middel van linked data kunnen ze verschillende datasets aan elkaar koppelen en zo de gegevens rijker maken.
Ga naar het volgende/vorige hoofdstuk
Je kan hieronder het volgende, het vorige of een ander hoofdstuk van het handboek ‘Open Data voor lokale besturen’ vinden.
De belangrijkste begrippen en het Open Data Charter
Welke meerwaarde kent open data?
Wat verdient extra aandacht?
Wat is de volgende stap?
Startpagina van het handboek